
File Information
| Property | Details |
|---|---|
| Software Name | Stable Diffusion WebUI |
| Version | v1.0.0-pre (latest) |
| License | AGPL-3.0 License |
| File Size | ~5 GB (varies by models & OS) |
| Developer / Publisher | AUTOMATIC1111 |
| GitHub Repository | Stable Diffusion WebUI |
| Supported Platforms | Windows, macOS (Intel & Apple Silicon), Linux |
| Category | AI Image Generation / Text-to-Image Tool |
Table of contents
Description
Stable Diffusion WebUI is the most powerful and feature-rich interface for AI image generation, built using the Gradio library. It offers a customizable, and offline-ready experience to run Stable Diffusion models locally with full control.
Whether you’re a digital artist, AI researcher, or creative professional, this tool gives you limitless generative AI capabilities right from your desktop.
Features of Stable Diffusion WebUI
| Feature Category | Description |
|---|---|
| Core Modes | Supports txt2img, img2img, outpainting, inpainting, color sketch, and prompt matrix. |
| Upscaling & Restoration | Includes RealESRGAN, CodeFormer, GFPGAN, SwinIR, LDSR, and ESRGAN for image enhancement. |
| AI Control Tools | Use attention prompts, negative prompts, variations, seed resizing, and highres fix. |
| Advanced AI Integrations | Supports LORAs, Hypernetworks, Textual Inversion, Composable Diffusion, and Aesthetic Gradients. |
| Community Extensions | Integrate scripts for checkpoint merging, auto history, custom scripts, and more. |
| Performance Optimizations | Built-in xformers support for faster generation on GPUs with 2GB–4GB VRAM. |
| User Experience | Includes live preview, progress bar, styles, batch processing, and parameter saving in images. |
| Cross-Platform Support | Works seamlessly on Windows, macOS, and Linux (NVIDIA, AMD, Intel GPUs supported). |
| Training Tab | Train your own embeddings, hypernetworks, and fine-tune models directly from the UI. |
| No Token Limit | Unlike default Stable Diffusion, prompts are unlimited in length for full creative freedom. |
Screenshots
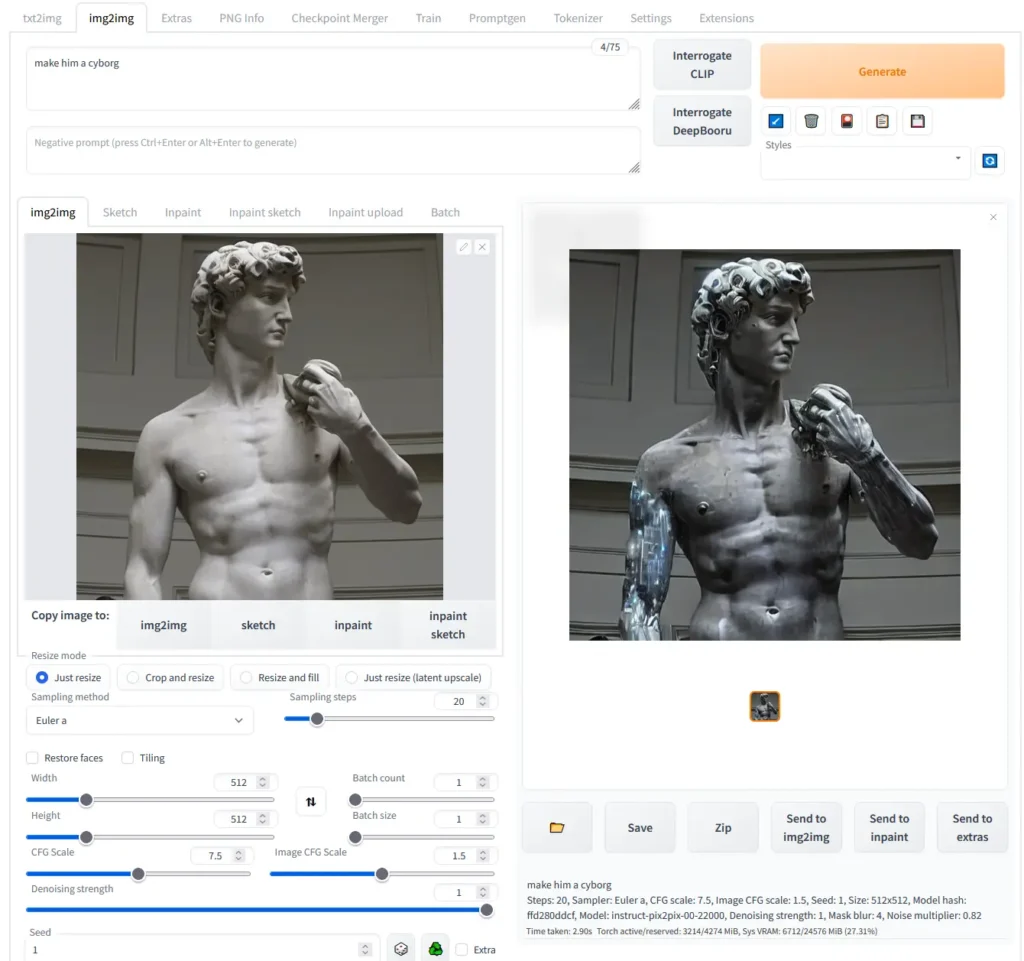
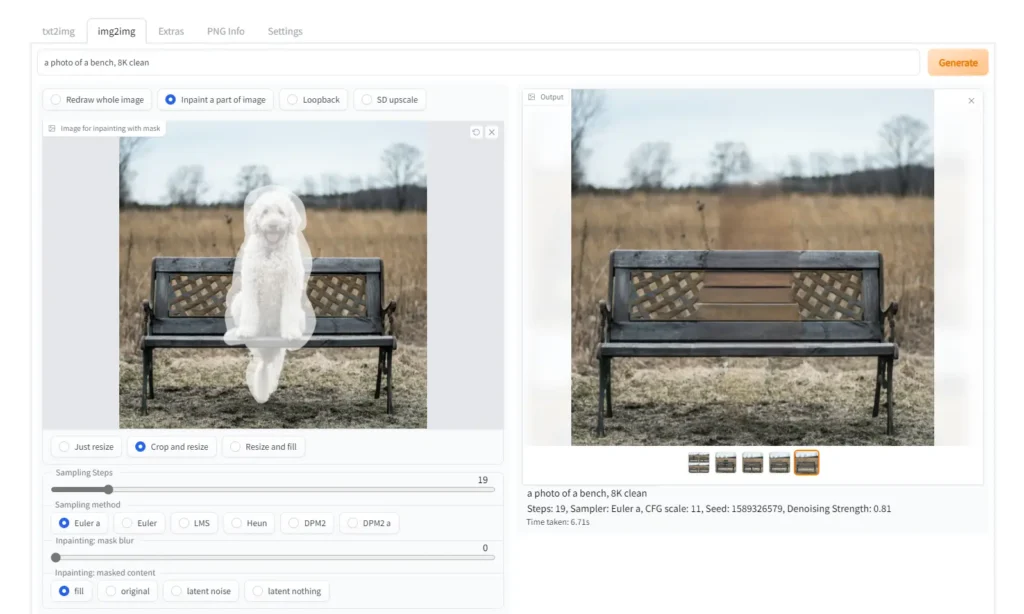
System Requirements
| Platform | Minimum Requirements |
|---|---|
| Windows | Windows 10 or 11, NVIDIA GPU with 4GB+ VRAM, Python 3.10.6, Git installed |
| macOS (Intel/Apple Silicon) | macOS 12+, Homebrew installed, Python 3.10, CMake, Rust, Protobuf |
| Linux | Ubuntu 20.04+, Python ≥3.10, Git, libgl1, libglib2.0, 4GB+ VRAM GPU (NVIDIA/AMD/Intel) |
| Storage | 15 GB free space (including model weights) |
| RAM | Minimum 8 GB (16 GB recommended) |
| Internet | Required for downloading models only; generation works offline |
How to Install Stable Diffusion WebUI??
Windows (NVIDIA Recommended)
- Download
sd.webui.zipfrom the download section below. - Extract contents and run
update.bat. - Launch
run.batto start the WebUI in your browser. - Alternatively, clone and run manually:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui webui-user.bat
macOS (Intel & Apple Silicon)
- Install Homebrew if not already installed.
- Run:
brew install cmake protobuf rust [email protected] git wget git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui cd stable-diffusion-webui ./webui.sh - Place your downloaded
.ckptor.safetensorsmodels inside/models/Stable-diffusion. if you don’t have any models downloaded then download them from download section below
Note: Some tools like CLIP Interrogator and training are slower on macOS due to limited GPU acceleration.
Linux (Debian, Fedora, Arch, etc.)
Step 1: Install Required Dependencies
Depending on your Linux distribution, run the appropriate command:
Debian / Ubuntu-based:
sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
Red Hat / Fedora-based:
sudo dnf install wget git python3 gperftools-libs libglvnd-glx
openSUSE-based:
sudo zypper install wget git python3 libtcmalloc4 libglvnd
Arch / Manjaro-based:
sudo pacman -S wget git python3
Step 2: Ensure Correct Python Version
If your system is very new, you might need to install Python 3.10 or 3.11 manually.
For Ubuntu 24.04 or newer:
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.11
For Manjaro / Arch:
sudo pacman -S yay
yay -S python311 # Do not confuse with python3.11 package
Then set the environment variable in the launch script:
export python_cmd="python3.11"
Or, edit the webui-user.sh file and add:
python_cmd="python3.11"
Step 3: Clone the Stable Diffusion WebUI Repository
Navigate to the directory where you want to install the web UI and run:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
Alternatively, you can download the main installation script directly:
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
Step 4: Launch the WebUI
Go into the cloned directory:
cd stable-diffusion-webui
Run the WebUI:
./webui.sh
Step 5: Optional Configuration
Check and edit webui-user.sh to customize:
- Python version
- VRAM optimization flags (
--medvram,--lowvram) - Other startup options
Once the setup completes, the WebUI will launch automatically in your browser (usually at http://127.0.0.1:7860).
Supported Models
| Model Name | Description |
|---|---|
| Stable Diffusion v1.4 / v1.5 | Classic models for high-quality, general-purpose generations. |
| Stable Diffusion 2.0 / 2.1 | Higher resolution (768×768+), better detail & structure. |
| Inpainting Models | Ideal for editing and reconstructing specific areas in images. |
| Depth Models (2.0 Depth) | Generates images using depth-aware diffusion for realistic scenes. |
| Custom Models | Supports .ckpt and .safetensors formats, including community-trained ones. |
Troubleshooting Tips
| Issue | Solution |
|---|---|
| WebUI won’t start | Delete repositories and venv folders, then run git pull before re-launching. |
| Slow performance | Use flags like --xformers, --medvram, or --lowvram. |
| Out of memory | Lower image resolution or enable split attention with --opt-split-attention-v1. |
| Model not found | Ensure .ckpt or .safetensors files are in the /models/Stable-diffusion directory. |
Why Choose Stable Diffusion WebUI?
- 100% local and private, no cloud dependency.
- Free and open-source under AGPL-3.0.
- Compatible with hundreds of community extensions and models.
- Offline capable once models are downloaded.
- Actively maintained with frequent updates and GPU optimizations.
Download Stable Diffusion WebUI
Download Stable Diffusion Models
You can download any model as per your requirement, it is not necessary to download all the models, below are SD models you can download:
Note: Stable Diffusion 2.0 and 2.1 require both a model and a configuration file, and image width & height will need to be set to 768 or higher when generating images:
Configuration in macOS
For the configuration file, hold down the option key on the keyboard and click here to download v2-inference-v.yaml (it may download as v2-inference-v.yaml.yml). In Finder select that file then go to the menu and select File > Get Info. In the window that appears select the filename and change it to the filename of the model, except with the file extension .yaml instead of .ckpt, press return on the keyboard (confirm changing the file extension if prompted), and place it in the same folder as the model (e.g. if you downloaded the 768-v-ema.ckpt model, rename it to 768-v-ema.yaml and put it in stable-diffusion-webui/models/Stable-diffusion along with the model).
Also available is a Stable Diffusion 2.0 depth model (512-depth-ema.ckpt). Download the v2-midas-inference.yaml configuration file by holding down option on the keyboard and clicking here, then rename it with the .yaml extension in the same way as mentioned above and put it in stable-diffusion-webui/models/Stable-diffusion along with the model. Note that this model works at image dimensions of 512 width/height or higher instead of 768.
For troubleshooting, visit the official documentation
Conclusion
Stable Diffusion WebUI is the definitive solution for anyone serious about AI image generation. From artists and developers to researchers and startups, it delivers studio-quality visuals right from your system — no subscriptions, no internet dependency, and full creative control.
With continuous updates, community extensions, and support for every major AI diffusion model, this tool stands as the gold standard of local AI image generation.



{kind=link}