
Most multimodal models are text models with image handling bolted on. A vision encoder reads the image, converts it into tokens the language model understands, and the two systems communicate through that translation layer. It works. It’s also where things break down when text and image content need to stay tightly in sync.
SenseNova-U1 takes a different approach. Released by SenseTime under Apache 2.0, it removes the visual encoder and VAE entirely. No translation layer or separate systems. Pixel and word information modeled together from the start.
The technical report isn’t out yet and the A3B variant is still pending. But the 8B weights are available now.
Table of Contents
How most multimodal models are built
The standard setup involves a text model, a separate vision encoder that reads images and converts them into tokens, and often a decoder on the other end for generating images. Three moving parts, stitched together. Each piece is trained somewhat independently and then connected.
When a model needs to reason about text and image content together, it’s essentially translating between two different representational systems. Most of the time it works fine. For tasks that need tight consistency between what’s written and what’s shown, that translation layer don’t work well. But SenseTime took a different approach.
What’s actually different here
NEO-Unify is the architecture SenseNova-U1 is built on. The idea is straightforward. They removed the visual encoder and the VAE entirely. Instead of having separate systems handle language and vision, pixel and word information are modeled together end to end from the start.
The practical result is that the model doesn’t translate between modalities. It thinks in both natively. Understanding an image, generating an image, editing an image, generating interleaved text and images in a single flow, all of it happens within one unified system.
What you can actually do with it

The capability list here is broader than most models at this size. On the understanding side it handles standard visual question answering, document parsing, chart comprehension, OCR, and agentic visual tasks. Feed it a screenshot, a PDF, a handwritten note, it processes all of it in the same model without switching modes.
On the generation side it does text-to-image, image editing, and native interleaved image and text generation. That means it can produce a cooking tutorial with step-by-step instructions and generated images inline, in a single output, without calling a separate image model. That’s the part that’s genuinely hard to do well and where the unified architecture pays off most visibly.
There’s also early Vision-Language-Action work happening on top of it, meaning the model can observe a visual scene and take actions within it. That’s still experimental but signals where SenseTime is pointing this.
If you’re interested in the image generation part of this model then there are many examples available on their github repo for you to see if its really worth it for your use case.
You May Like: Best AI Coding Models for Consumer Hardware
Benchmarks
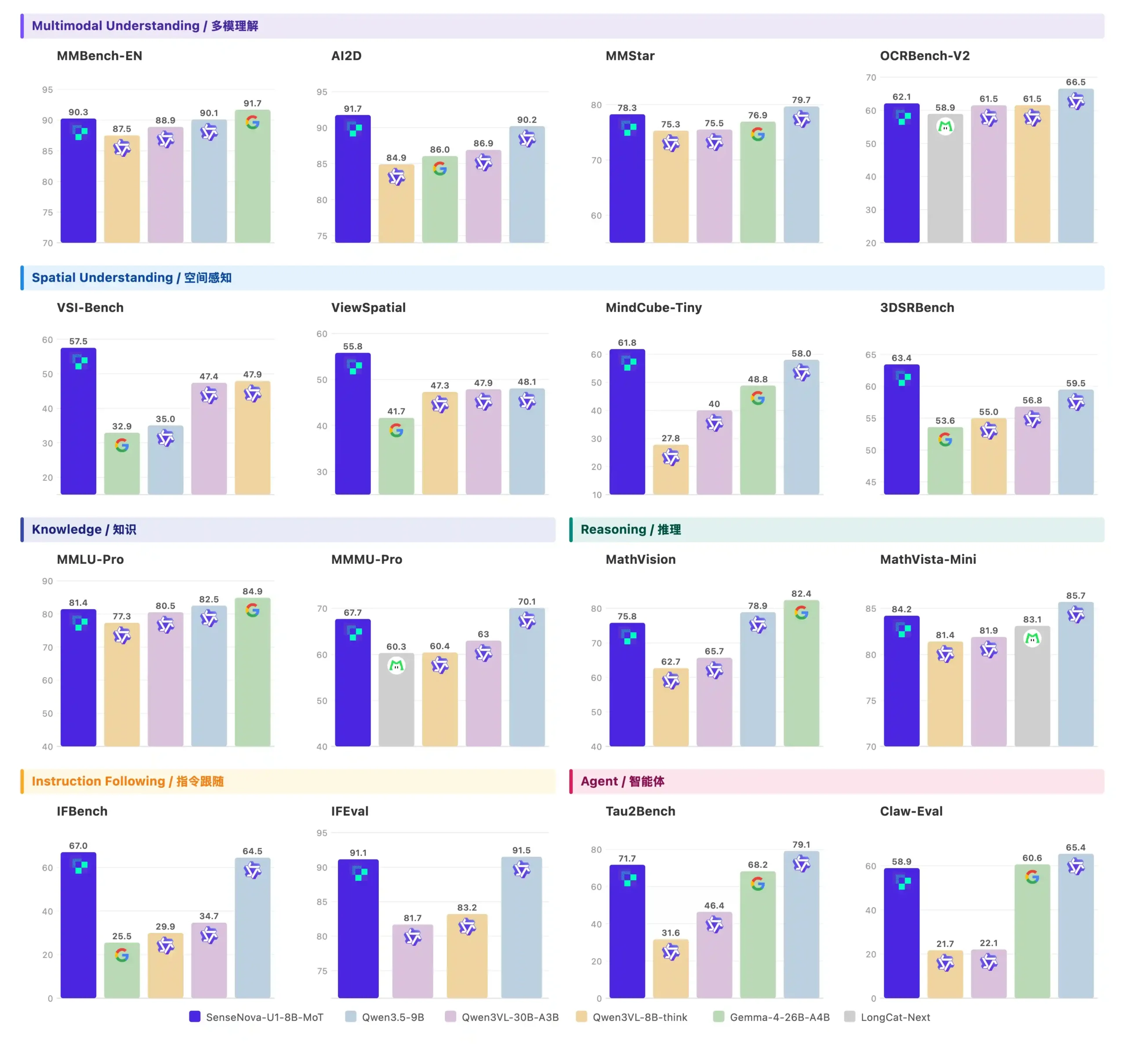
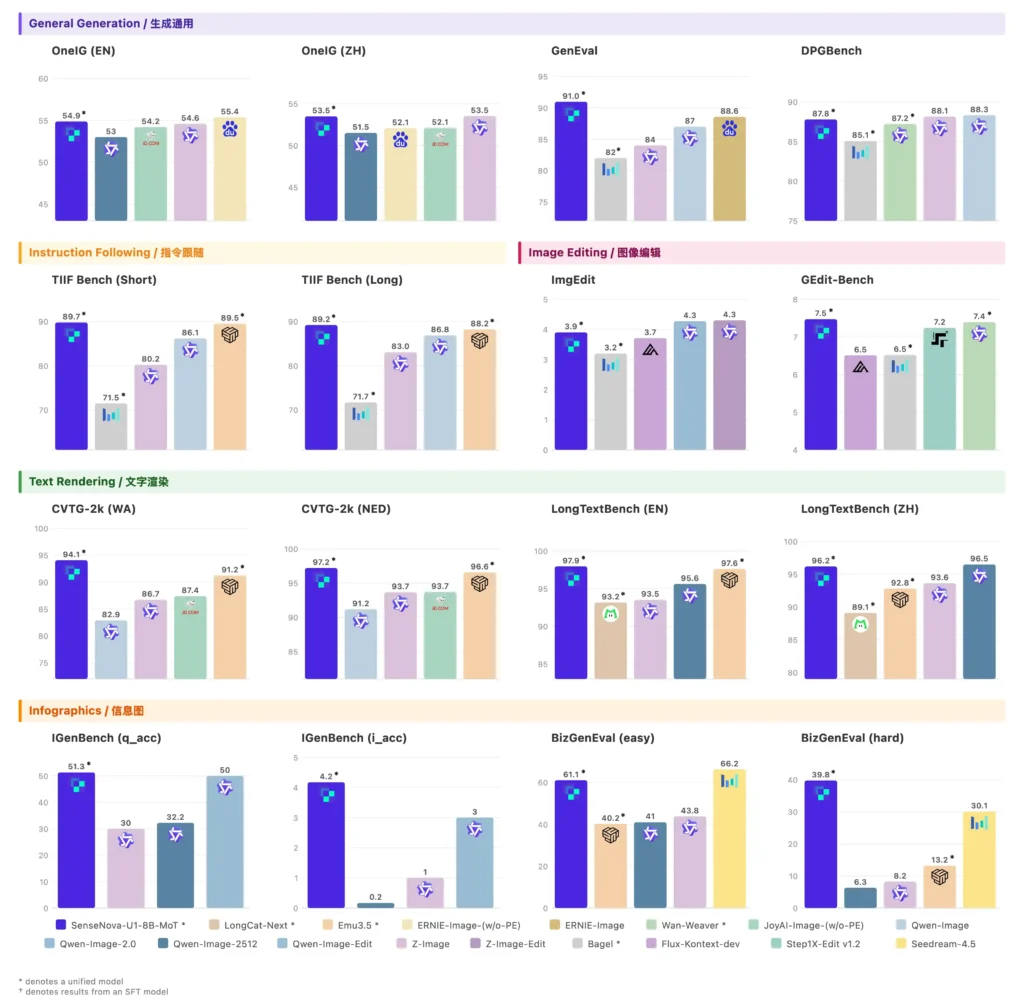
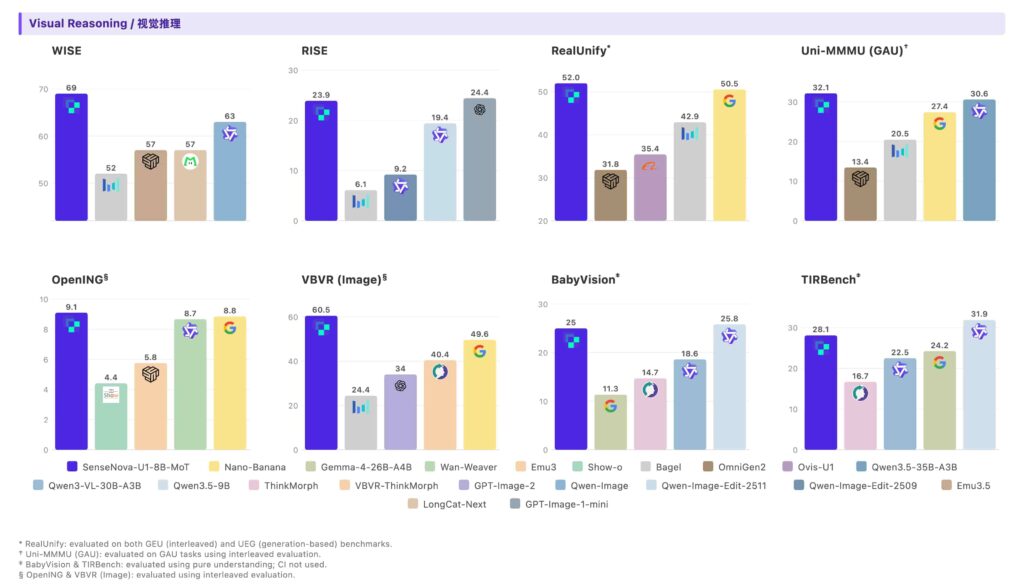
Most of this is self-reported using SenseTime’s own evaluation setup and the technical report isn’t out yet.
That said, a few results are worth calling out. On spatial reasoning via VSI-Bench the 8B scores 57.5 against Qwen3VL-8B-think’s 47.9. MindCube-Tiny puts it at 61.8 versus 27.8 for the same Qwen model. Spatial and 3D reasoning is where unified architectures theoretically have an advantage and these numbers suggest that’s not just theoretical.
On generation, GenEval comes in at 91.0, the strongest result on that chart. Text rendering inside generated images has been a stubborn problem for most image models for years. CVTG-2k scores 94.1 here, ahead of dedicated editing models.
On visual reasoning VBVR Image scores 60.5 against Nano Banana’s 49.6. Even though its not the new Nano Banana Model yet the gap is worth considering.
8B by Name, 18B on Disk
SenseNova-U1 currently has one available variant, the 8B-MoT dense backbone. The A3B-MoT MoE version is listed in the repo but weights aren’t out yet.
Before you pull from Hugging Face, one thing worth knowing. The 8B label refers to understanding parameters only. Generation adds roughly another 8B on top, so what you’ll actually see listed is 18B total weights. Plan your hardware before pulling.
There’s also an 8-step inference preview variant now available that cuts generation time significantly with image quality that stays close to the base model in most cases. Worth trying if inference speed matters for your use case.
The A3B-MoT is listed as coming. When it drops it should run considerably lighter than the 8B given the 3B active parameter count. We’ll update this page when it’s available.
Where it still falls short
The context window sits at 32K tokens. For a multimodal model handling documents, long videos, or complex visual contexts that’s a big constraint. Most competing models at this size offer significantly more headroom.
Human body generation is still inconsistent. Fine-grained details break down when people appear small in a scene or are interacting with surrounding objects in complex ways. If your use case involves generating people doing things, results will vary.
Text rendering inside generated images can produce misspellings or distorted characters, especially in text-heavy layouts. SenseTime recommends using prompt enhancement before generating infographics for best results. It helps, but the problem isn’t fully solved.
Interleaved generation is still experimental. It’s one of the most interesting capabilities on paper but RL training hasn’t been specifically optimized for it yet. Current performance is on par with SFT models. It works, it’s just not the finished version.
Fastest way to try it
The quickest path is SenseNova Studio, a free browser playground. Good for getting a feel for what the model actually does before committing to anything local. It requires a free account before you can access the playground.
For local use, the weights are on Hugging Face under SenseNova. Setup runs through transformers with uv for dependency management. If you’re building an agent or application on top of it, OpenClaw ships SenseNova-U1 as a ready-to-use skill with a unified tool-calling interface, which saves a lot of wiring.
For production serving the recommended stack is LightLLM for understanding and LightX2V for generation running together. An official Docker image is available for one-command deployment if you want to skip the manual setup.
Apache 2.0 across the board.
You May Like: AI Image Generators You Can Run on Consumer GPUs
Still Early. Still Worth Your Attention
SenseNova-U1 is an incomplete release by its own admission. The technical report isn’t out, some weights are pending and interleaved generation is still being refined. What’s available now is enough to evaluate seriously but not enough to draw final conclusions.
Removing the visual encoder and VAE entirely is a real departure from how most multimodal models are built. If it holds up at larger scales and SenseTime has explicitly said larger versions are planned, it could change how this category of model gets built.
The open source model space has a habit of moving faster. This one is worth keeping an eye on.



{kind=link}