
IBM just released Granite 4.1, a family of open source language models built specifically for enterprise use. Three sizes, Apache 2.0 licensed, trained on 15 trillion tokens with a level of pipeline obsession that’s worth understanding.
One result in the benchmarks doesn’t make sense until you understand how they built it.
The 8B model. Dense architecture, no MoE tricks, no extended reasoning chains. It matches or beats Granite 4.0-H-Small across basically every benchmark they ran. That older model has 32 billion parameters with 9 billion active. This one has 8 billion.
That’s either very impressive or it means the old model was underbuilt. Probably both.
Here’s how they built it, what the numbers actually say, and whether any of it matters for your use case.
Table of Contents
The result that makes you do a double take
On ArenaHard, a benchmark where models are judged by GPT-4 on how well they handle 500 challenging real-world prompts, it’s one of the better proxies for actual chat quality. The 8B instruct scores 69.0 there. The previous generation Granite 4.0-H-Small, a 32B MoE model with 9B active parameters, scored lower. On BFCL V3, the standard tool calling benchmark. The 8B scores 68.3, the 32B MoE scores 64.7. GSM8K is grade-school math reasoning, and the 8B hits 92.5 there too. Across AlpacaEval, MMLU-Pro, BBH, EvalPlus, MBPP. same thing throughout.
A denser, simpler, smaller model is winning. Consistently.
It actually means IBM got significantly better at training between generations. The 4.0-H-Small wasn’t badly built, it was the best they had at the time. The 4.1 8B is what happens when you spend the intervening period obsessing over data quality instead of just scaling parameters. That’s the thread running through everything about how Granite 4.1 was built.
Three sizes, one obsession: how they actually built this
Granite 4.1 comes in 3B, 8B, and 30B. All three use the same decoder-only dense transformer design, the same training pipeline and same data strategy. The only difference between them is size. No MoE routing, sparse layers or extended reasoning chains that inflate token counts. What you send in is what gets processed, predictably, every time.
Models that lean on long reasoning traces are harder to cost-predict and harder to latency-budget. Granite 4.1 skips all of that by design. But the architecture isn’t really the story. The story is the 15 trillion tokens they trained on and how carefully they handled them.
IBM ran five distinct training phases with different data mixtures, different learning rate schedules, and different goals. Phase 1 is broad: CommonCrawl at 59%, code at 20%, math at 7%. By Phase 2, math has jumped to 35% and code to 30%. By Phases 3 and 4, they’re blending in chain-of-thought reasoning trajectories and instruction data alongside the highest-quality web content they have. Phase 5 extends the context window, eventually to 512K tokens for the 8B and 30B.
Most teams pick a data mix and stick with it. IBM changed theirs four times with clear intent each time.
You May Like: Laguna XS.2 Feels Like a Model That Was Never Meant to Be Public. It Now Is.
The filter that rejected bad data before it could do damage
IBM spent enough time on their data quality pipeline that it deserves its own explanation.
After pre-training, they needed to turn the base model into something that actually follows instructions reliably. That requires fine-tuning on examples of good behavior but bad examples in that dataset don’t just get ignored. They get learned. A hallucinated answer, a response that ignores the instruction, a calculation that’s wrong but confident, the model treats all of it as signal.
So IBM built a filtering system before a single fine-tuning sample touched the model. An LLM-as-Judge evaluated every assistant response across six dimensions including instruction following, correctness, completeness, conciseness, naturalness, and calibration. Each response got scored, and samples that fell below threshold got cut. But some things triggered automatic rejection regardless of score, hallucinations, false premises, incorrect computations. No partial credit for those.
The judge wasn’t reading prompts or user inputs in isolation. It was evaluating what the model said given the full context it had access to. In RAG settings, if the response wasn’t grounded in the retrieved documents, that counted as a hallucination. In tool-calling scenarios, outputs were checked against the allowed tools and their parameter schemas.
On top of that, a separate rule-based pipeline checked structure like length, formatting, schema validation, deduplication across the entire dataset. Everything was logged and auditable.
What came out the other side was 4.1 million samples. That sounds like a lot. For context, it’s a deliberately curated 4.1 million.
Four rounds of RL and why they needed all of them
This is the part of the Granite 4.1 paper that I find most interesting, mostly because it’s honest about something going wrong mid-training and how they fixed it.
After fine-tuning, IBM ran reinforcement learning in four sequential stages. The first stage trained the model jointly across nine domains at once including math, science, logical reasoning, instruction following, structured output, text-to-SQL, temporal reasoning, general chat, and in-context learning. The reason for doing all of them together is that joint training prevents the model from forgetting earlier domains as it gets better at later ones. Every gradient update sees the full range of tasks.
Stage two was RLHF training on general chat prompts using a reward model to improve helpfulness. This worked. AlpacaEval scores jumped around 18.9 points on average compared to the fine-tuned checkpoints.
Then something broke. The RLHF stage, while improving chat quality, caused math benchmark scores to drop. GSM8K and DeepMind-Math both regressed.
Stage three was a short identity and knowledge calibration run about 40 training steps to stabilize how the model represents itself and what it knows. Small stage, measurable improvement on self-identification.
Stage four was a dedicated math RL run specifically to recover what RLHF had damaged. It worked, GSM8K recovered and surpassed the fine-tuned baseline by around 3.8 points on average. DeepMind-Math recovered by around 23.5 points on average.
You May Like: Open-Source TTS Models That Can Clone Voices and Actually Sound Human
The benchmarks
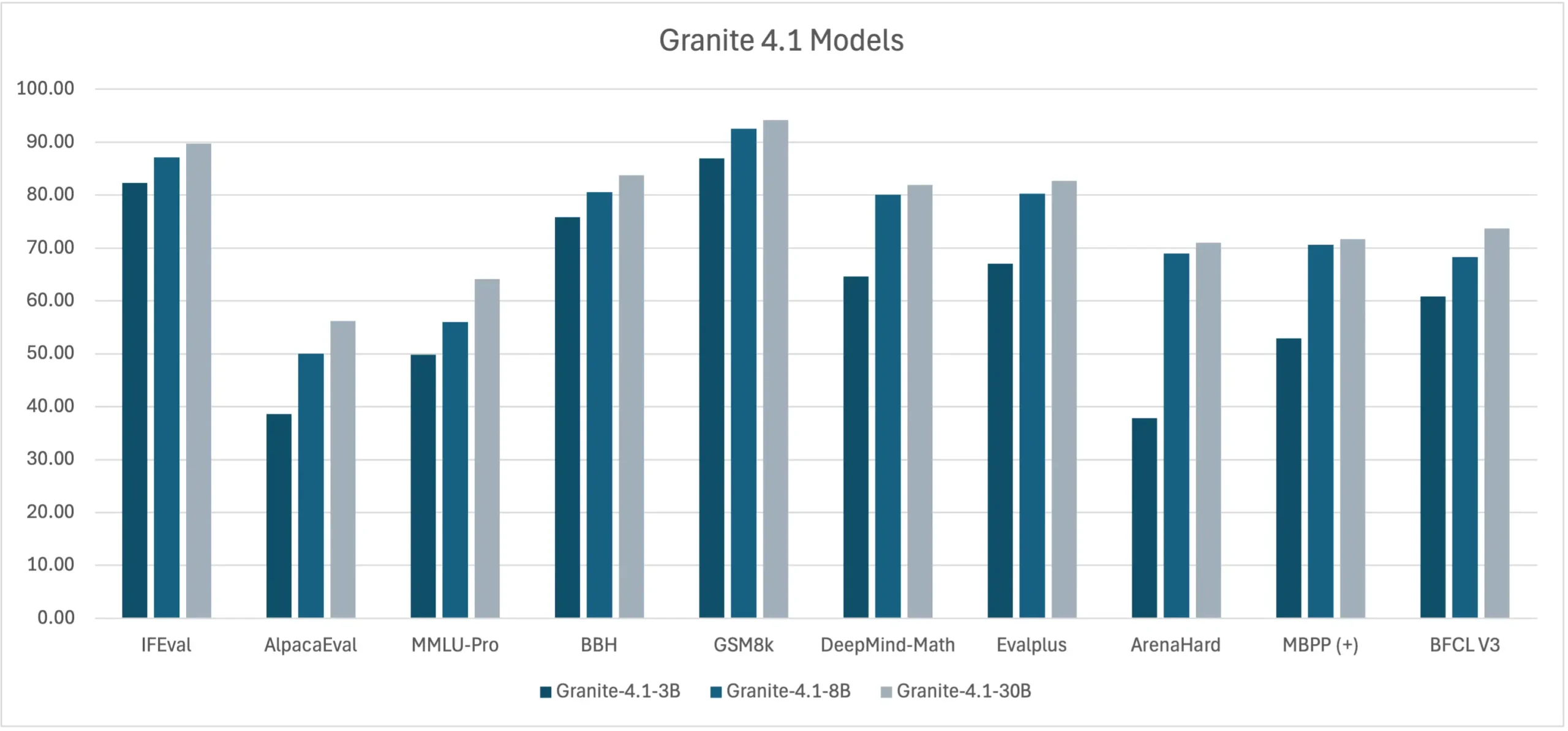
| Benchmark | What it tests | 3B | 8B | 30B |
|---|---|---|---|---|
| IFEval | Instruction following | 82.1 | 87.1 | 89.7 |
| BFCL V3 | Tool calling | 60.8 | 68.3 | 73.7 |
| GSM8K | Math reasoning | 87.0 | 92.5 | 94.2 |
| DeepMind-Math | Advanced math | 64.6 | 80.1 | 81.9 |
| EvalPlus | Coding | 67.1 | 80.2 | 82.7 |
| ArenaHard | Real-world chat quality | 37.8 | 69.0 | 71.0 |
| MMLU-Pro | General knowledge | 49.8 | 56.0 | 64.1 |
The 30B sits at the top of IBM’s own BFCL V3 tool calling chart at 73.7, ahead of Gemma-4-31B at 72.7. That’s a legitimate leaderboard result, not a cherry-picked internal comparison. The 8B at 68.3 beats the previous Granite 4.0-H-Small at 64.7, and the 3B at 60.8 still clears Qwen3-8B at 60.2, a model twice its size.
On instruction following via IFEval, Gemma leads at 94.1 and that’s worth saying plainly. But the 8B at 87.1 is essentially tied with Qwen3.5-9B at 87.2, and the 30B at 89.7 beats every Qwen model on the chart regardless of size.
On math, the 8B hits 92.5 on GSM8K and 80.1 on DeepMind-Math. The 30B pushes those to 94.2 and 81.9. On coding, EvalPlus puts the 8B at 80.2 and the 30B at 82.7. MBPP+ scores 70.6 and 71.7 respectively.
The 3B is the quiet story here. 82.1 on IFEval, 87.0 on GSM8K, 60.8 on BFCL V3. For something running at that parameter count, those numbers are hard to ignore if you’re thinking about edge deployment or cost-constrained inference.
One honest caveat across all of this, the comparison charts are IBM’s own, using their own evaluation harness. The absolute numbers are plausible and consistent with what third parties have reported, but benchmark methodology always deserves scrutiny. These are self-reported results.
512K context: how they got there without breaking short-context
Getting a model to handle 512K tokens is one problem. Getting it to handle 512K tokens without forgetting how to handle 4K tokens is a different and harder problem.
IBM solved it with a staged extension approach inside Phase 5 of pre-training. They didn’t jump straight to 512K. They went 32K first, then 128K, then 512K. Each stage used the same data mix as Phase 4 until the final extension, where they switched to 80% books and 20% code repository data for the 8B and 30B models specifically. Books and long code repositories are natural long-context data they have coherent structure across tens of thousands of tokens in a way that web data doesn’t.
After each extension stage, IBM did a model merge. This is the part that protects short-context performance. By merging the long-context checkpoint back with earlier weights rather than just continuing to train, they preserved the behaviors the model had already learned at shorter lengths.
The RULER benchmark which tests whether long-context capability is real or just superficially present shows the 8B base scoring 83.6 at 32K, 79.1 at 64K, and 73.0 at 128K. The 30B holds up better: 85.2, 84.6, and 76.7. There’s degradation as context grows, which is expected and honest, but the scores don’t fall off a cliff.
The 3B only extends to 128K, not 512K. Worth knowing if long context is a hard requirement for your use case.
You may Like: OpenMythos: The Closest Thing to Claude Mythos You Can Run (And It’s Open Source)
How to run it?
The quickest way in is Ollama. Pull whichever size fits your hardware, the 3B runs comfortably on most consumer machines, the 8B needs a bit more headroom, and the 30B is a GPU machine job. All three are on Hugging Face under ibm-granite if you want to go that route instead.
For production use, vLLM and Transformers both support the models out of the box. If you want to evaluate before committing to any local infrastructure, IBM has the models available through their API as well.
The FP8 quantized variants are worth trying if memory is a constraint, roughly half the footprint of the full precision versions with most of the performance intact.
Apache 2.0 across the board, so commercial use is clean.
Who should care
If you’re building something that needs reliable tool calling, predictable latency, and a license that won’t create legal headaches down the line, Granite 4.1 deserves a serious look. The 8B is the sweet spot, genuinely competitive with models that cost more to run, and honest enough in its benchmarks that you’re not walking into surprises at deployment.
The 3B is interesting for anyone thinking about edge use cases or tight inference budgets. The 30B is for when you need the ceiling and have the hardware to match.
What IBM built here is a production-first model family from a team that clearly spent more time fixing problems than announcing them. The four-stage RL pipeline that caught and corrected a mid-training regression is the kind of detail that doesn’t make headlines but absolutely shows up in real-world reliability.




{kind=link}