
Poolside AI spent years building AI for governments and public sector clients, the kind of organizations with security requirements so strict that most software never gets near them. Air-gapped deployments, on-premise infrastructure, clearance levels most developers don’t think about. That’s the world Poolside was operating in while the rest of the AI industry was racing to ship consumer products.
Laguna XS.2 is their first open source release. Its Apache 2.0 Licensed, weights on HuggingFace, runs on a Mac with 36GB of RAM and available on Ollama right now. A model trained on the same infrastructure with the same rigor as something built for high security government environments, free for anyone to download and build with.
That backstory matters because it shapes what this model actually is. It wasn’t built to win a benchmark leaderboard. It was built to work reliably on hard problems in environments where failure is not an option. The open source release is almost an afterthought, a decision to share what they’ve learned.
Table of Contents
What Laguna XS.2 actually is
At 33B total parameters with only 3B active per token, Laguna XS.2 sits in a weight class most people can actually run. It can run on a Mac with 36GB of RAM via Ollama. That’s meaningful accessibility for a MOE model performing at this level.
The architecture uses sliding window attention in 30 of its 40 layers with per-head gating, which keeps KV cache requirements low and inference fast without sacrificing quality on longer contexts. The context window is 128K tokens. Native reasoning support is built in with interleaved thinking between tool calls, and you can enable or disable it per request depending on what the task needs.
It’s a coding and agentic model specifically. Poolside is explicit about this, they believe coding is the core skill through which most other agent capabilities get expressed. An agent that can write and execute code can compose actions, build its own tools, and interact with the world in ways that pure tool-calling agents can’t. Laguna XS.2 is built around that belief.
The fastest way in is their API, free for a limited time. Ollama works for local deployment. vLLM and Transformers are both supported with day one compatibility. There’s also a lightweight terminal agent called pool that Poolside built and released alongside the model, designed to work with their Agent Client Protocol.
The other model Poolside released the same day
Laguna XS.2 is the open source release but it has a larger sibling called Laguna M.1. It has 225B total parameters with 23B active, trained from scratch on 30T tokens across 6,144 NVIDIA Hopper GPUs. It completed pre-training at the end of last year and is what Poolside considers their most capable model to date.
It is not open source. But it is available via their API for free for a limited time alongside XS.2, which means you can compare both on your actual workload before committing to either.
On SWE-bench Verified M.1 scores 72.5 and on Terminal-Bench 2.0 it hits 40.7. Solid numbers for a model at that scale, though several open source models now sit above it on the same benchmarks. The more interesting question is what it looks like after further post-training, and Poolside has signaled that both models will continue to improve.
What the benchmarks show
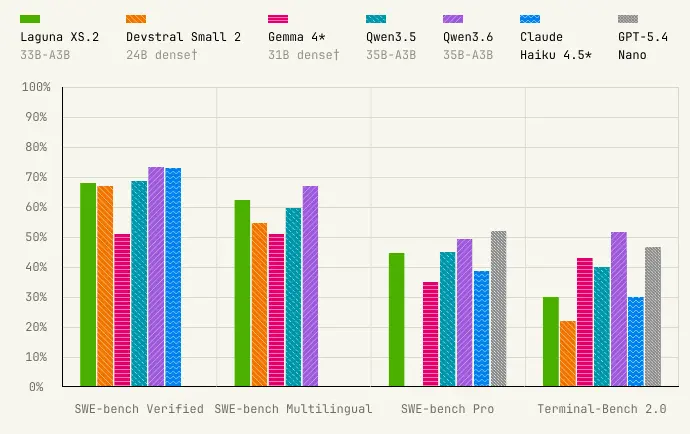
All benchmarking was done using Poolside’s own agent harness with their own sandboxed execution environment. The methodology is documented and reasonable but it is worth knowing the context when comparing against numbers run under different conditions.
| Benchmark | Laguna XS.2 | Qwen3.6-35B | Claude Haiku 4.5 | Devstral Small 2 | Gemma 4 31B |
|---|---|---|---|---|---|
| SWE-bench Verified | 68.2 | 73.4 | 73.3 | 68.0 | 52.0 |
| SWE-bench Multilingual | 62.4 | 67.2 | n/a | 55.7 | 51.7 |
| SWE-bench Pro | 44.5 | 49.5 | 39.5 | n/a | 35.7 |
| Terminal-Bench 2.0 | 30.1 | 51.5 | 29.8 | 22.5 | 42.9 |
Laguna XS.2 does not top every column. Qwen3.6-35B beats it across the board on these benchmarks and Claude Haiku 4.5 leads on SWE-bench Verified. Where XS.2 holds its own is on SWE-bench Pro against Haiku 4.5 at 44.5 vs 39.5, and on multilingual coding against Devstral Small 2.
What the benchmarks don’t capture is the long-horizon agentic performance, which is where Poolside’s training approach is most differentiated. Standard SWE-bench tasks are relatively short horizon. The async agent RL pipeline they built was designed for trajectories spanning hundreds of tool calls, which is a different problem than what most benchmark tasks measure.
Related: MiMo-V2.5-Pro Is Now Open Source and It’s Sitting Right Next to Claude Opus 4.6 on Coding
How it was built differently
Most model releases mention their training approach briefly and move on. Poolside’s is worth understanding because it explains why this model behaves the way it does on long agentic tasks.
They used the Muon optimizer across all training stages, which they claim achieved the same training loss as AdamW in roughly 15% fewer steps. The efficiency gains are real enough that they built a distributed implementation to handle the compute overhead at scale. Across both Laguna models the optimizer overhead stayed under 1% of total training step time, which at this scale is a meaningful efficiency gain.
The agent RL setup is genuinely different from most approaches. Rather than waiting for full batches of trajectories before updating the model, they built a fully asynchronous system where actors generate data continuously and the trainer consumes it at its own pace. This matters specifically for long-horizon tasks. If you wait for a complete trajectory spanning hundreds of tool calls before taking a training step, your GPUs sit idle most of the time and long trajectories get systematically underrepresented in training. Their async approach solves both problems.
They also built an automixing framework called AutoMixer that trains roughly 60 proxy models on different data mixes, fits surrogate regressors to understand how each mix affects downstream performance, then optimizes from there. The result is a learned mapping from data composition to model capability, which is more principled than the manual heuristics most labs use.
Synthetic data makes up about 13% of the final training mix, built on top of organic data rather than replacing it. They applied synthetic generation across the broader data mix, not just narrow STEM and code domains, which they say improves generalization without sacrificing signal density.
How to run it today
The easiest starting point is Ollama. One command pulls the model and you are running it locally.
For production use vLLM and Transformers both have day one support. TRT-LLM works too with NVIDIA Blackwell getting an NVFP4 variant for strong performance on that architecture. There is also a free API if you want to evaluate before committing to local infrastructure.
Recommended sampling parameters are temperature 0.7 and top_k 20. Native reasoning is on by default with interleaved thinking between tool calls. You can disable it per request if your use case doesn’t need it.
Related: Open-Source TTS Models That Can Clone Voices and Actually Sound Human
Who should care
Developers who want a capable agentic coding model running entirely on their own hardware. The Mac compatibility at 36GB RAM is the most accessible local deployment story at this benchmark level right now.
Teams in regulated or security-conscious environments. The fact that this model was built for high security government deployments and is now Apache 2.0 licensed is a combination you don’t see often. On-premise deployment with no data leaving your infrastructure is a realistic option here.
Researchers studying long-horizon agent training. Poolside published enough detail on their async RL setup, AutoMixer, and Muon implementation to make this genuinely interesting from a research perspective.
And if you have been waiting for a serious open source coding model that you can run on a Mac today, pull it from Ollama and see how it handles your actual codebase. That is a more honest evaluation than any benchmark table.



{kind=link}