
Every developer who has worked with long context models knows the feeling. You paste in your codebase, add your requirements, include some examples, and somewhere around the halfway point the model starts forgetting things it read at the top. You get generic answers. It misses files it already saw. The context window is technically full but the model is functionally half-asleep.
This is called the performance cliff and it is the real problem with long context AI, not the number itself. DeepSeek-V4 is making a specific claim here. Not just that it supports 1M tokens, several models do that now. The claim is that it stays useful across that entire window by fundamentally changing how attention works at scale. In the 1M token setting, V4-Pro requires only 27% of the compute per token and 10% of the KV cache compared to DeepSeek-V3.2.
It is MIT licensed. Weights are on HuggingFace right now. And they shipped two models simultaneously, which means there is an actual choice to make depending on what you are building.
Table of Contents
Two models, one decision
DeepSeek-V4 comes in two variants. Pro at 1.6T total parameters with 49B active per token, and Flash at 284B total with 13B active. Both support the full 1 million token context window.
The active parameter number is what matters for inference cost, not the total. Pro activates 49B per token, Flash activates 13B. Flash is cheaper to run and still competitive on most benchmarks. Pro is where you go when you need maximum reasoning depth on the hardest tasks.
Think of it this way. Flash is the model you run in production at volume. Pro is the model you run when the task genuinely needs the full weight of 49B active parameters thinking through it. Both use FP4 precision for MoE experts and FP8 for most other parameters, which keeps memory requirements more manageable than the raw numbers suggest.
For most developers the honest starting point is Flash. Move to Pro when Flash hits a ceiling on your specific task.
How they made 1M tokens actually efficient
Standard attention has a quadratic problem. The more tokens you add, the more expensive every computation becomes, and the more memory you need to store the context. At 1M tokens this becomes genuinely brutal. Most models that support long context are doing it expensively and paying for it in either quality or cost.
DeepSeek-V4 uses two attention mechanisms working together. Compressed Sparse Attention handles most layers with a narrow sliding window, only attending to nearby tokens rather than the entire context. Heavily Compressed Attention handles a smaller number of layers with global reach but aggressive compression. The result is that the model maintains awareness of the full context without paying full attention cost at every layer.
They also added Manifold-Constrained Hyper-Connections on top of standard residual connections. The practical effect is more stable signal propagation across layers, which matters a lot when you are processing a million tokens and information needs to travel a long way through the network without degrading.
The Muon optimizer replaced Adam during training, which DeepSeek says delivered faster convergence and more stable training runs at this scale.
Put together these changes explain the 27% compute and 10% KV cache numbers. The model is not just bigger, it is structurally different in how it handles length.
One Model with Three Modes
Both V4-Pro and V4-Flash support three reasoning modes and the difference between them is significant enough to affect how you build with it.
Non-think mode gives you fast direct responses. No visible reasoning, low latency, good for routine tasks where speed matters more than depth. Think High is where the model reasons through the problem before answering, slower but meaningfully more accurate on complex tasks. Think Max pushes reasoning as far as the model can go, requires a larger context window of at least 384K tokens, and is designed for tasks where you genuinely need the ceiling.
The benchmark gap between modes is not subtle. HMMT is a prestigious math competition benchmark, the kind of problems that take human contestants hours. On HMMT 2026, V4-Flash in Non-think mode scores 40.8. The same model in Think Max scores 94.8. HLE, Humanity’s Last Exam, is one of the hardest knowledge and reasoning benchmarks available, designed to stump even expert humans. Non-think gives you 8.1 on it. Think Max gives you 34.8. Same model, same weights, completely different capability depending on how much reasoning budget you give it.
That gap is not about the model getting smarter. It is about giving it time to actually think. This matters practically because you do not need to choose a different model for different task types. You choose a mode. Routine queries run cheap on Non-think. Hard problems get Think Max when the answer actually matters.
The part most people skip
Supporting 1M tokens is easy to claim. Actually staying useful across that entire window is a different problem.
DeepSeek published two benchmarks that test this honestly. MRCR, which measures how well a model retrieves and reasons over information buried deep inside a massive context, and CorpusQA, which tests question answering across extremely long documents. Both evaluated at the full 1M token length. On MRCR, V4-Pro scores 83.5 against Gemini 3.1 Pro at 76.3. On CorpusQA it scores 62.0 against Gemini’s 53.8. Claude Opus 4.6 scores 92.9 on MRCR but drops to 71.7 on CorpusQA. These are self-reported numbers but the pattern holds. V4 maintains coherence at lengths where most models quietly degrade.
The post-training story is also worth understanding. DeepSeek didn’t train one model on everything simultaneously. They trained separate domain-specific expert models first, each one specialized in its own area, then consolidated them into a single model through on-policy distillation. The practical result is a model that performs consistently across coding, math, and reasoning rather than being strong in one domain and mediocre everywhere else. That consistency is harder to achieve than the benchmark numbers suggest and it explains why V4 doesn’t have obvious weak spots the way some frontier models do.
What the benchmarks show
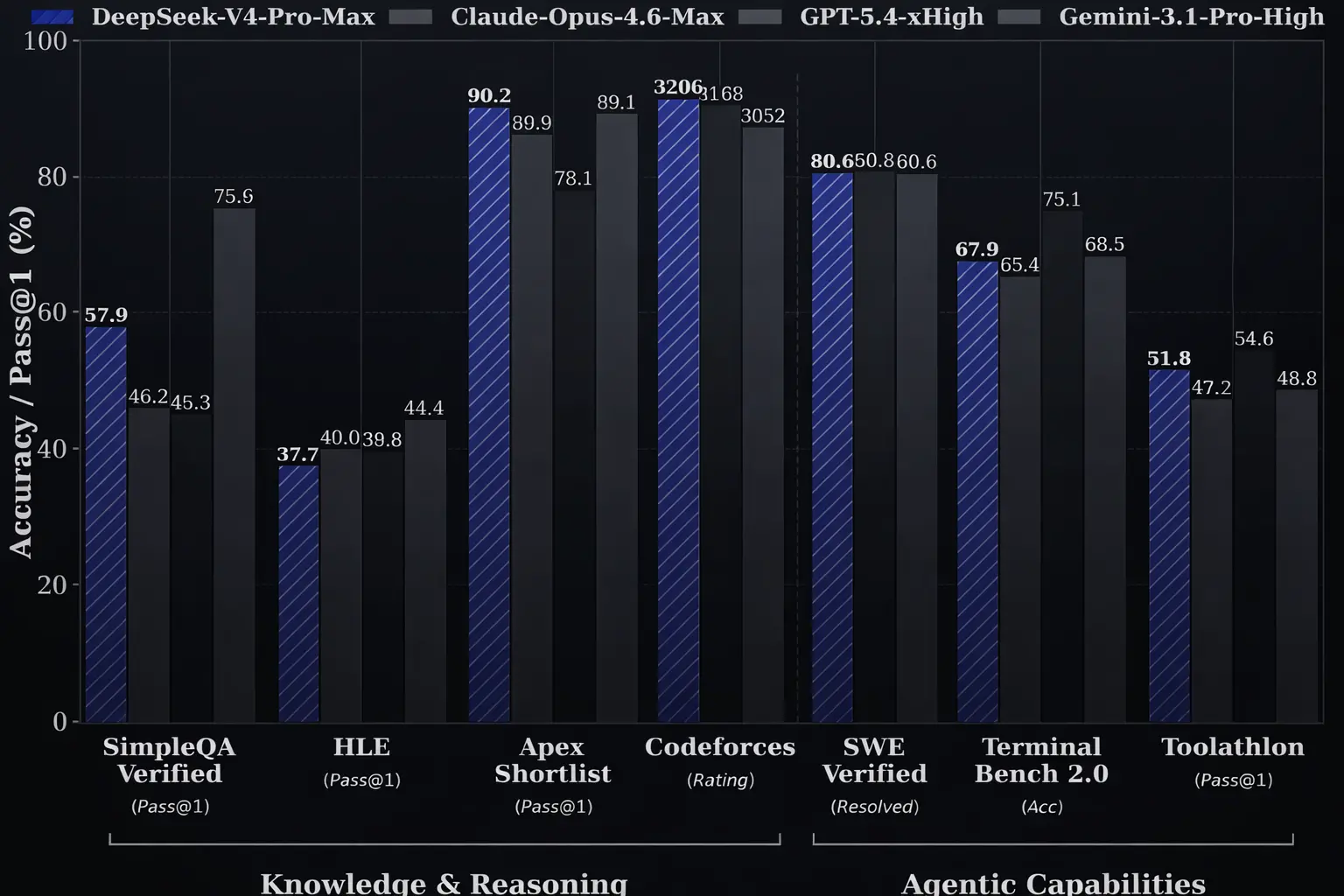
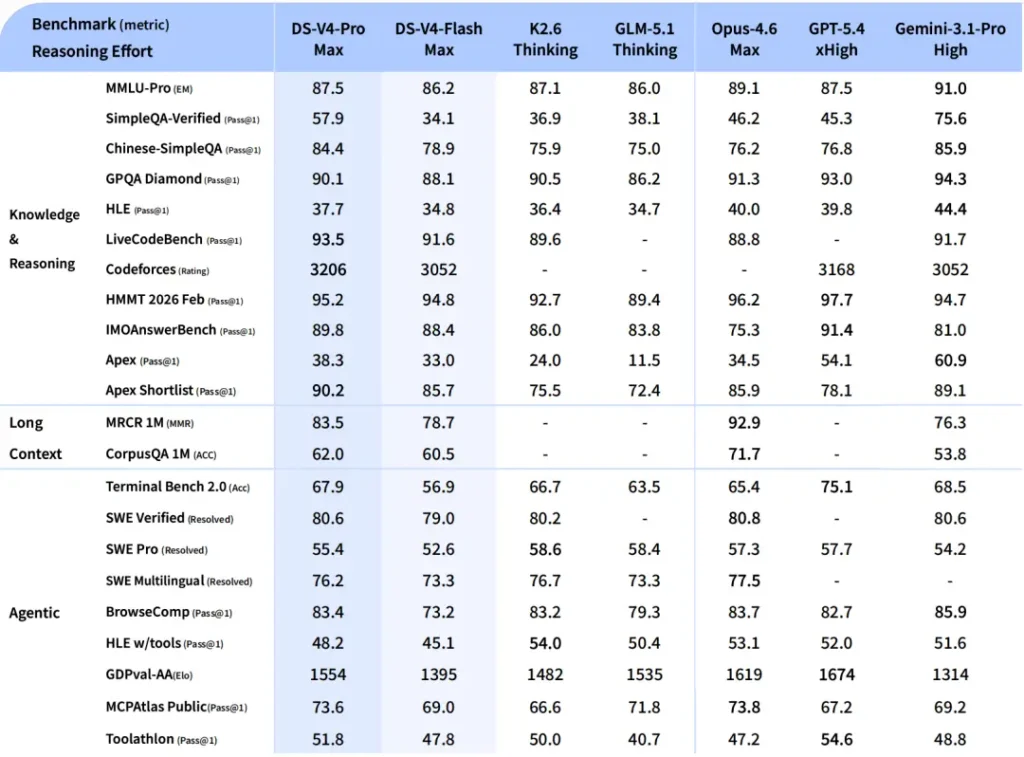
| Benchmark | V4-Pro Max | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| LiveCodeBench | 93.5 | 88.8 | n/a | 91.7 |
| SWE Verified | 80.6 | 80.8 | n/a | 80.6 |
| SWE Pro | 55.4 | 57.3 | 57.7 | 54.2 |
| BrowseComp | 83.4 | 83.7 | 82.7 | 85.9 |
| GPQA Diamond | 90.1 | 91.3 | 93.0 | 94.3 |
On LiveCodeBench V4-Pro leads the group. On SWE benchmarks it sits within a point or two of Claude Opus 4.6 and Gemini 3.1 Pro. On pure reasoning benchmarks like GPQA Diamond and HLE it trails the top closed models. This is a coding and long context model first, general reasoning model second. The benchmarks reflect that accurately. One thing worth knowing is that these are self-reported numbers from DeepSeek. We’ve trimmed the table to the benchmarks that tell the most honest story. Full results are on the DeepSeek HuggingFace page.
Related: MiMo-V2.5-Pro: A Coding Model Taking On Claude Opus 4.6 and GPT-5.4
How to run it
For local deployment DeepSeek recommends temperature 1.0 and top_p 1.0. Think Max mode needs at least 384K context window. The model uses a custom chat template so you will need the encoding scripts from the repo rather than a standard Jinja template. The encoding folder has Python scripts and test cases that walk you through it. SGLang is the recommended inference engine for serious deployments.
Realistically V4-Pro at 1.6T parameters is not a consumer hardware project. Flash at 284B with 13B active is more approachable but still needs serious infrastructure. If you want to run either locally right now, the API is the honest answer for most people.
The good news is the ecosystem is already moving. DeepSeek-V4 is available on OpenRouter. More providers will follow quickly, that’s been the pattern with every major DeepSeek release. Quantized versions from the community will also show up on platforms like Ollama as people work through the weights, which is typically when local deployment becomes realistic for developers without a cluster.
Until then the API route through OpenRouter or DeepSeek’s own platform is where most people will get their first real time with it.
Cloud pricing
If you’re thinking to use DeepSeek’s own platform then the pricing is competitive for what you get.
| Model | Input (cache hit) | Input (cache miss) | Output | Context |
|---|---|---|---|---|
| V4-Pro | $0.145 | $1.74 | $3.48 | 1M |
| V4-Flash | $0.028 | $0.14 | $0.28 | 1M |
Cache hits matter more here than with most models. If you are running repeated queries against the same large codebase the cached input price on V4-Pro drops from $1.74 to $0.145 per million tokens. That changes the economics significantly for long context workflows where the same files appear across many requests.
V4-Flash at $0.14 per million input tokens is genuinely cheap for a model performing at this level. Worth starting there before deciding if V4-Pro’s extra depth justifies the cost on your specific workload.
Related: Open Source LLMs That Rival ChatGPT and Claude
Who this is for
Developers working with large codebases who keep hitting context limits with current models. If your workflow involves feeding entire repositories into a model, V4 is the open source option where the architecture is specifically designed to handle that without degrading.
Researchers who need genuine long document understanding at 1M tokens. The CorpusQA results at 1M context are the most honest test of whether long context actually works, and V4-Pro holds up where most models fall apart.
Teams running agentic workflows at scale who want frontier-competitive performance without closed model pricing. MIT license means you build commercially without any conversation about terms.
And if you have been watching DeepSeek since V3 and wondering when the open source community would get a genuine 1M context model that actually works efficiently at that length, this is that release.



{kind=link}