
Peking University gives its computer science students a compiler project every semester. Build a complete SysY compiler in Rust including lexer, parser, abstract syntax tree, IR code generation, assembly backend, performance optimization. The whole thing. Students typically need several weeks.
MiMo-V2.5-Pro finished it in 4.3 hours. Perfect score. 233 out of 233 tests passed on a hidden test suite it had never seen. That’s a real university project and a model that scored higher than most students who spent weeks on it. Xiaomi built this, which is still a sentence that takes a moment to process.
V2.5-Pro is the next step up from MiMo-V2-Flash and its now Open Source. What V2.5-Pro adds over Flash is meaningful. Better long-horizon coherence, stronger agentic capabilities, and the ability to sustain complex tasks across more than a thousand tool calls without losing the thread.
That’s not a benchmark row. That’s a story. And it’s the most honest way to explain what Xiaomi thinks it has built here.
Table of Contents
Three things it built while nobody was watching
The compiler story is the most dramatic but it’s not alone.
After the compiler, Xiaomi gave it a vaguer prompt like build a video editor. No detailed spec or anything specific. What came back after 11.5 hours and 1,868 tool calls was a working desktop application with a multi-track timeline, clip trimming, crossfades, audio mixing, and an export pipeline. The final codebase was 8,192 lines. A working product built start to finish while the humans presumably went home.
The third test went somewhere most coding benchmarks don’t touch. A graduate-level analog circuit design task specifically a Flipped-Voltage-Follower low-dropout regulator in a TSMC 180nm process. This is the kind of work that takes trained analog engineers several days. MiMo-V2.5-Pro was wired into an ngspice simulation loop, called the simulator, read the waveforms, adjusted parameters, and iterated. About an hour later every target metric was met. Line regulation improved 22 times over its own initial attempt. Load regulation improved 17 times.
What connects all three isn’t just capability. It’s discipline. The compiler had a regression at turn 512, a refactoring pass broke two tests. The model caught it, diagnosed the failure, and recovered without being told to. That kind of self-correction across hundreds of tool calls is what separates a model that can code from one that can actually finish something.
What the benchmarks say
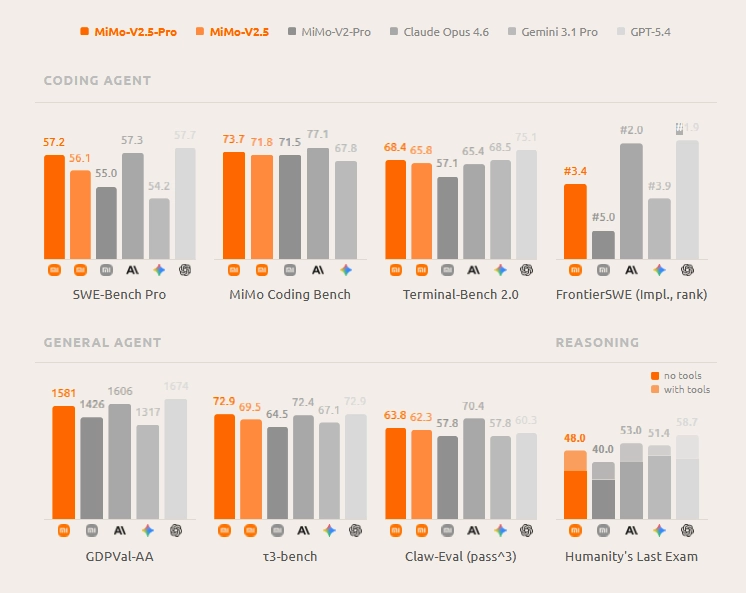
We’ve trimmed this to the rows that compares bigger models. Full results are on their official site.
| Benchmark | MiMo-V2.5-Pro | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | DeepSeek V4 Pro |
|---|---|---|---|---|---|
| SWE-Bench Pro | 57.2 | 57.3 | 57.7 | 54.2 | 55.4 |
| SWE-Bench Verified | 78.9 | 80.8 | n/a | 76.2 | 80.6 |
| Terminal-Bench 2.0 | 68.4 | 65.4 | 75.1 | 68.5 | 67.9 |
| Claw-Eval Pass@3 | 63.8 | 70.4 | 60.3 | 57.8 | 59.8 |
| HLE with tools | 48.0 | 53.0 | 58.7 | 51.4 | 48.2 |
| GDPVal-AA | 1581 | 1606 | 1674 | 1317 | 1554 |
The pattern is consistent though. On SWE-Bench Pro MiMo-V2.5-Pro sits within half a point of Claude Opus 4.6 and GPT-5.4. On Terminal-Bench 2.0 it actually leads Opus 4.6 and Gemini. On Claw-Eval it beats GPT-5.4 and Gemini comfortably. Where it lacks is HLE and GDPVal-AA, both of which reward broad general reasoning over focused coding depth. This is a coding-first model and the numbers reflect that honestly.
On Claude Sonnet 4.6 specifically Xiaomi didn’t publish a direct comparison but their token efficiency chart places both models on the same graph. On Claw-Eval Pass@3 MiMo-V2.5-Pro scores 63.8. Sonnet 4.6 sits noticeably lower on the same benchmark according to that chart. For an open source model you can now download and run yourself, that gap is worth paying attention to.
You May Like: Open Source LLMs That Rival ChatGPT and Claude
MiMo vs DeepSeek V4 Pro: two open source giants, one decision
Both are live on HuggingFace right now. Both are MIT licensed. Both target developers who want frontier-competitive coding performance without paying closed model prices. So which one?
The honest answer depends on what you’re building.
On raw coding benchmarks they’re closer than you’d expect. SWE-Bench Pro is 57.2 for MiMo against 55.4 for DeepSeek V4 Pro. Terminal-Bench 2.0 goes 68.4 vs 67.9. SWE-Bench Verified is 78.9 vs 80.6. No clean winner, just different edges on different tasks.
Where they actually differ is architecture and cost. DeepSeek V4 Pro activates 49B parameters per token from a 1.6T total. MiMo-V2.5-Pro activates 42B from 1.02T. MiMo is the more parameter-efficient model and the token efficiency story we covered earlier makes that real in production, fewer tokens per trajectory at comparable quality levels.
DeepSeek V4 Pro has the stronger general reasoning story. MiMo V2.5 Pro has the stronger agentic coding story, especially on long-horizon tasks where the three demos made the case better than any benchmark row could.
If you’re running an agentic coding workflow that needs to sustain thousands of tool calls, MiMo is the pick. If you need a model that handles coding and general reasoning equally well across a 1M context window, DeepSeek V4 Pro is worth the comparison.
Both are worth running. Neither is the obvious universal winner.
What actually changed at long context
Most models that claim long context support quietly fall apart past a certain point. They technically accept the tokens but the quality degrades fast. You get generic answers, missed details, responses that ignore things the model read earlier in the context.
The previous MiMo-V2-Pro had this problem. Past 128k tokens it degraded rapidly. At 1M tokens it scored zero on both subtasks of GraphWalks, a long context benchmark from OpenAI that fills the prompt with a directed graph and asks the model to run breadth-first search or identify parent nodes across the full context length.
V2.5-Pro is a different story. At 512k tokens it scores 0.56 on BFS and 0.92 on Parents. At the full 1M token length it scores 0.37 and 0.62 respectively. Not perfect but genuinely functional at a length where the previous version had completely given up.
The architectural reason is the hybrid attention design. Local Sliding Window Attention handles most layers using only a 128 token window, which keeps memory costs manageable. Global Attention layers handle the broader context reach. The two work together so the model stays anchored to the full context without paying full attention cost at every layer. KV cache storage drops by nearly 7x compared to standard attention at this length.
What this means practically is that feeding an entire large codebase, a full research paper collection, or a long running agent conversation into a single context window is now actually viable with this model in a way it wasn’t before.
The token efficiency nobody is talking about
Benchmark scores get all the attention. Token costs are what actually determine whether developers adopt a model in production.
On ClawEval, MiMo-V2.5-Pro hits 64% Pass@3 using roughly 70,000 tokens per trajectory. Xiaomi claims that’s 40-60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 reach comparable scores with. These are self-reported figures so treat them directionally, but if accurate the cost difference at production scale is significant.
That gap compounds fast. If you’re running hundreds of agentic tasks a day, the difference between 70K tokens and 120K tokens per trajectory isn’t marginal. It’s the difference between a workflow that’s economically viable and one that isn’t.
This is the part of MiMo-V2.5-Pro that doesn’t show up in the headline comparisons but matters most to anyone building on top of it.
Related: Xiaomi Quietly Released an AI Model That Challenges DeepSeek Here’s Why It Matters
There’s also a multimodal version: The one that sees, hears, and reads
While everyone focuses on V2.5-Pro, Xiaomi also dropped another model in the same release. MiMo-V2.5 is the omnimodal sibling, same family, same MIT license, but built to handle text, image, video, and audio all within a single unified architecture.
It’s 310B total parameters with 15B active per token, so significantly lighter than V2.5-Pro. Same hybrid attention design, same 1M token context window, trained on 48T tokens total. It has a dedicated 729M parameter vision encoder and a 261M parameter audio encoder built in, not bolted on as an afterthought.
Two variants here as well. MiMo-V2.5-Base is the foundation model at 256K context if you want to fine-tune for specific multimodal tasks. MiMo-V2.5 is the full instruct model with 1M context ready to use out of the box.
The download is 316GB so plan accordingly. SGLang and vLLM both supported, same deployment approach as V2.5-Pro.
If your use case involves processing images, audio, or video alongside text in a single model without stitching together multiple systems, this is worth looking at seriously. For pure coding and agentic work V2.5-Pro remains the stronger pick.
How to run it
Weights are on HuggingFace right now. Two variants including MiMo-V2.5-Pro is the full instruct model with 1M token context, MiMo-V2.5-Pro-Base is the base model at 256K context if you want to fine-tune from scratch. Both are 1.02T total parameters in FP8 mixed precision.
MIT license means clean commercial use, no attribution requirements, no scale thresholds to worry about.
The honest deployment reality is that 1.02T parameters needs serious infrastructure. SGLang is the recommended inference engine with official community support and a dedicated cookbook for this model. vLLM works too. Recommended sampling parameters are temperature 1.0 and top_p 0.95. For complex agentic tasks Xiaomi recommends pairing it with a proper harness, the compiler and video editor demos both used one.
For most people the API through Xiaomi’s platform is still the practical starting point. No waitlist, switch the model tag to mimo-v2.5-pro and you’re using it. Pricing hasn’t changed from V2-Pro. It also works with Claude Code, OpenCode, and Kilo if you’re already running an agentic scaffold.
Community quantized versions will show up as people work through the weights, that’s been the pattern with every major open source release at this scale.
Who should care
Developers running agentic coding workflows at any real volume. The token efficiency advantage makes it worth evaluating against whatever you’re currently paying for, closed or open.
Teams working on long horizon tasks that keep hitting context limits. If your workflow involves large codebases, long agent trajectories, or documents that push past 128k tokens, the architectural improvements here are real and measurable.
Researchers who want a frontier competitive open source model to build on, fine tune, or study. MIT license, weights available, no restrictions.
And if you’ve been watching Xiaomi’s AI lab wondering whether they’re serious, three demos, weights dropped, MIT licensed, benchmarks sitting next to Opus 4.6. That’s a pretty clear answer.



{kind=link}