
Researchers figured out how to make AI reason more efficiently by having AI figure it out itself. By building an environment where an AI agent writes controller code, tests it, gets feedback, and rewrites it until the strategy gets better.
The result cuts token usage by roughly 70% at the same accuracy as running 64 parallel reasoning chains. That’s the difference between inference being affordable and inference being a cost problem.
The research comes from a team across UMD, UVA, WUSTL, UNC, Google, and Meta. It’s called AutoTTS, automated test-time scaling and it’s one of the more conceptually interesting papers published this year even if you can’t download a model and use it tomorrow.
Table of Contents
What it actually discovered
The standard approach to getting better answers from a reasoning model is brute force. Run the same question through the model 64 times in parallel, collect all the answers, pick the most common one. It works but it’s also expensive, 64x the compute for every single query.
AutoTTS asked a different question. Instead of running more parallel chains and hoping majority vote wins, can a system automatically discover smarter strategies for when to branch, when to keep going, when to stop, and when to cut a reasoning path that’s going nowhere?
The answer it found is called the Confidence Momentum Controller. Rather than making fixed decisions about inference, always branch this many times, always run this many steps, the CMC watches how confident the model is across its reasoning traces and makes decisions based on trends.
If confidence is rising consistently, it stops early and answers. If confidence stagnates or drops, it opens new branches and explores. If one branch is consistently agreeing with the emerging consensus, it gets more compute. If another branch keeps diverging, it gets cut but only after persistently deviating, not on a single bad step.
The CMC wasn’t designed by a researcher. It was written by an AI agent, tested against cached reasoning traces, evaluated on accuracy and token cost, and rewritten over multiple rounds until it stopped improving. The humans built the environment. The agent wrote the policy.
The numbers that matter
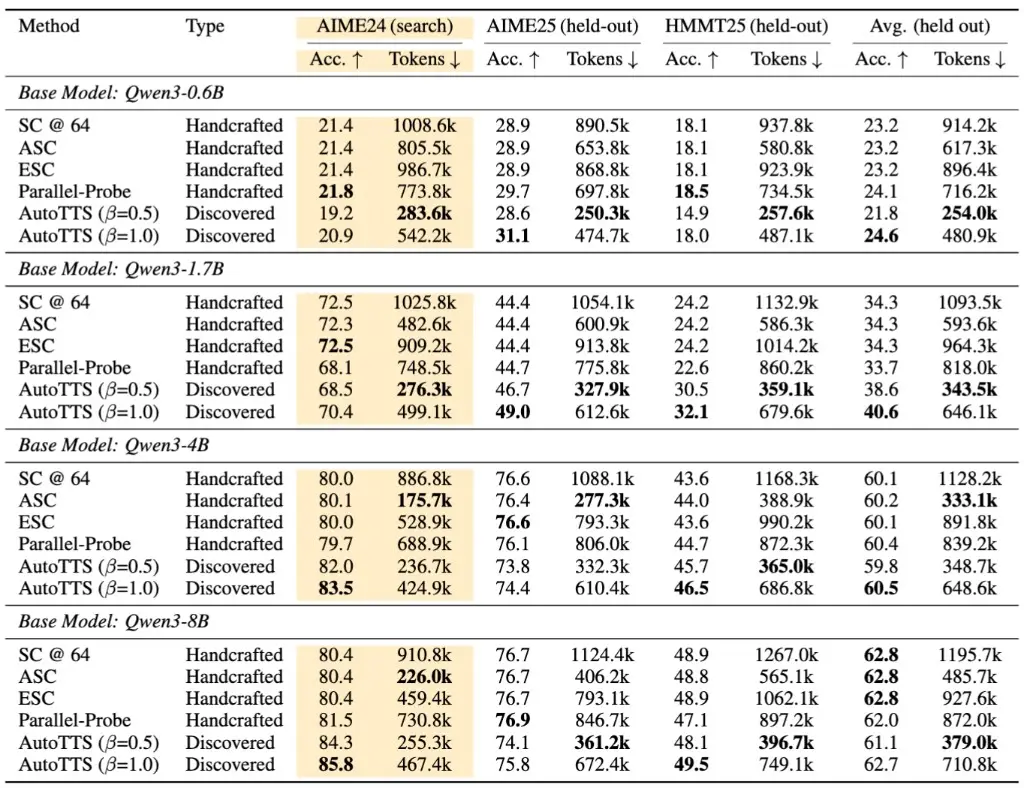
At the β = 0.5 operating point, the balanced setting between speed and accuracy. AutoTTS cuts token usage by roughly 69.5% compared to running 64 parallel chains. Accuracy on held-out benchmarks matches SC@64 across four different Qwen3 model sizes. Matching at 30% of the token cost.
At β = 1.0, the accuracy-first setting, the discovered controller pushes peak accuracy beyond every handcrafted baseline in five of eight comparison cells across the benchmark table. More accurate and discovered automatically.
The evaluations ran on AIME24 for discovery and held out AIME25 and HMMT25 for testing. The controller generalized policies discovered on one benchmark transferred to benchmarks the system never saw during search. That’s the result that matters most for anyone skeptical about whether this is just benchmark overfitting.
How it works
The system has two parts and it’s worth understanding both because the elegance is in how they fit together.
First, before any discovery happens, you collect reasoning traces offline. Run your model on a set of questions, save every reasoning path, chunk each path into fixed-length segments. This becomes your replay store, a cached database of how the model actually reasons across thousands of problems.
Second, a Claude Code agent writes controller code. The controller decides inference strategy, when to branch, when to stop, when to probe a reasoning path, when to cut it. The agent tests each controller against the replay store without making any new model calls. Everything is cached. A full discovery run costs $39.90 in API calls and takes 160 minutes. The replay store does the heavy lifting.
Each round the agent gets back accuracy numbers, token costs, and detailed traces of exactly what the controller did on each problem including where it branched, where it stopped, where it was wrong. It uses that feedback to rewrite the controller. Repeat for several rounds until the objective stops improving.
Its Just an agent writing increasingly better Python code in a feedback loop. The offline collection runs once per model and benchmark. After that, discovery is cheap enough that a research team can run multiple experiments in a day.
You May Like: Open Source AI Models That Actually Get Text Right in Generated Images
Who can actually use this today
You cannot download AutoTTS and plug it into your deployment tomorrow. There are no pretrained weights that gives you a 70% token reduction on your existing system. What exists is a research framework, a replay environment, and the discovered controller code.
To actually use this you need to collect your own offline reasoning traces from your target model, thousands of cached responses across your benchmark of interest. You need Claude Code running with API access for the discovery loop. You need engineering time to set up the replay environment and evaluate results. The $39.90 discovery cost assumes all of that infrastructure is already in place.
For ML researchers and inference engineers at teams actively working on test-time compute, this is immediately actionable. The framework is open, the discovered CMC controller ships with the repo and can be evaluated on their replay data without running discovery at all.
For most developers building on top of frontier models via API, this is a paper to understand and watch. The ideas will show up in production inference systems probably sooner than you’d expect, but that work hasn’t happened yet.
When the Strategy Writes Itself
Every inference efficiency gain so far has come from humans designing better strategies. AutoTTS is the first published system where the strategy design itself is automated and the discovered strategy beats the hand-designed ones.
It means inference efficiency research scales with compute and replay data rather than with how many researchers can think carefully about the problem.
This is early. One paper, one controller, two benchmarks. But the question AutoTTS is asking, can AI systems automatically discover better ways to use their own intelligence is one of the most important questions in the field right now. This paper has a credible answer for at least a narrow version of it.
Worth watching even if you can’t use it today.



{kind=link}