
Baidu has been doing search longer than most AI companies have existed. While OpenAI was still a research lab and Anthropic hadn’t been founded yet, Baidu was already the dominant search engine for 1.4 billion people. Search is not something they learned recently.
So when ERNIE 5.1 lands 4th on the Search Arena global leaderboard above Gemini 3.1 Pro with Grounding, above GPT-5.4 search and even above Google’s own search-augmented model, it’s surprising only if you forgot who built it.
Most Western AI coverage treats ERNIE as a footnote. These numbers suggest that’s worth reconsidering.
Table of Contents
4th Globally on Search. Above Google’s Gemini.
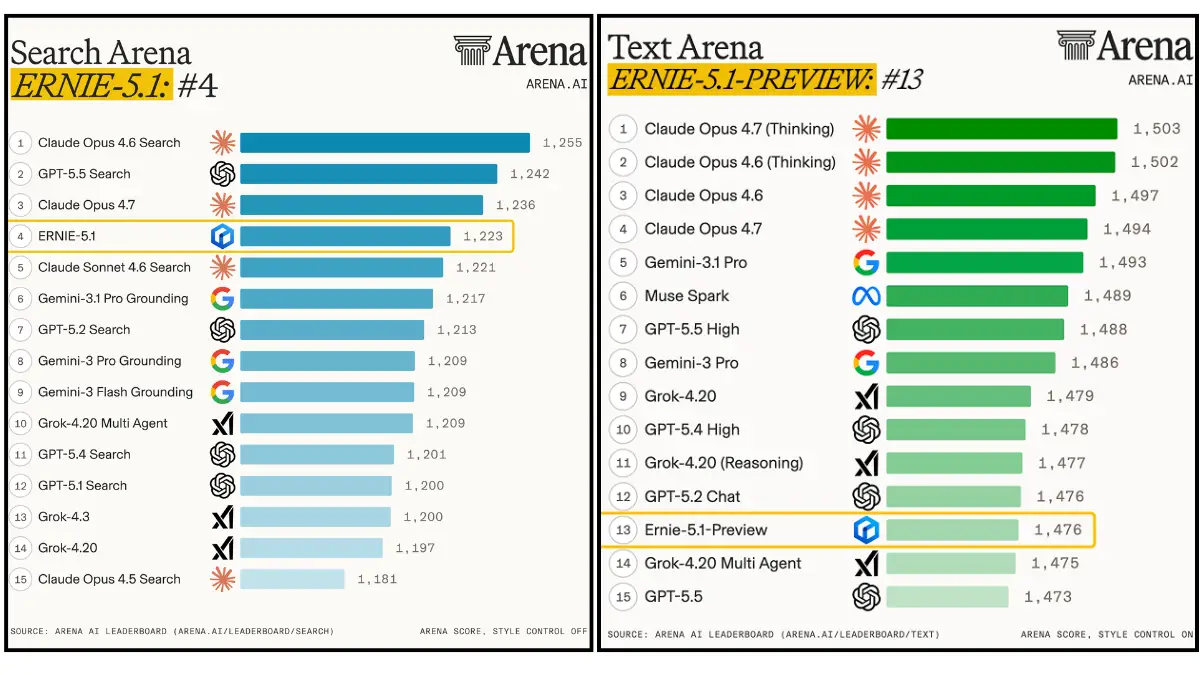
Search Arena is an independent evaluation where real users compare how well different models answer questions that require searching and reasoning over current information. The kind of task where knowing a lot isn’t enough, the model has to find the right information, understand it, and produce a useful answer.
ERNIE 5.1 scores 1,223 Elo on Search Arena. Claude Opus 4.6 Search leads at 1,255. GPT-5.5 Search sits at 1,242. ERNIE is behind both but ahead of Claude Sonnet 4.6 Search, Gemini 3.1 Pro with Grounding, and every other model on that leaderboard.
For a model that most Western developers haven’t touched and most Western coverage hasn’t covered seriously, that placement deserves more than a footnote.
The text Arena tells a similar thing. ERNIE 5.1 Preview sits 13th globally at 1,476 Elo between GPT-5.5 and Grok-4.20 Multi Agent. These are global evaluations with actual competition from the models everyone talks about.
The benchmark numbers
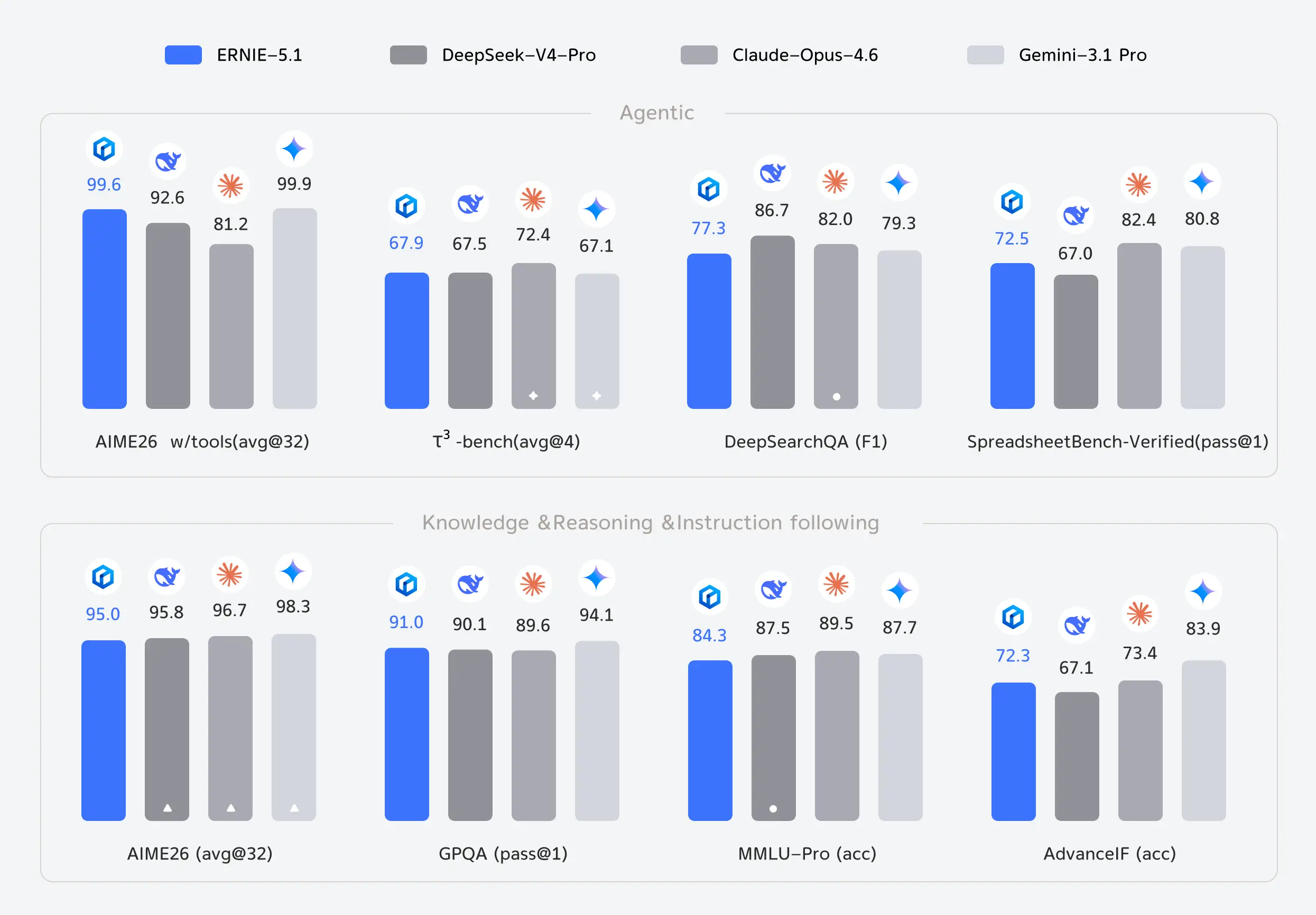
AIME26 with tools at 99.6 puts ERNIE 5.1 second only to Gemini 3.1 Pro at 99.9 on competition mathematics with tool use. DeepSeek V4 Pro scores 92.6 on the same benchmark. Claude Opus 4.6 scores 81.2. The gap between ERNIE and the next closest model on that specific benchmark is not small.
τ3-bench, which tests multi-step agent execution across realistic scenarios, scores 67.9 narrowly ahead of DeepSeek V4 Pro at 67.5 and Gemini 3.1 Pro at 67.1. Claude Opus 4.6 leads that chart at 72.4.
SpreadsheetBench tests whether a model can handle real spreadsheet reasoning tasks — the kind of structured data work that comes up constantly in actual business workflows. ERNIE scores 72.5, ahead of DeepSeek V4 Pro at 67.0 and Gemini 3.1 Pro’s result.
But before reading too much into any of this. Baidu published these benchmarks. Most of the comparison numbers come from their own evaluation setup. The Search Arena and text Arena results are independently verified which is exactly why those two numbers are the ones worth leading with.
The technical bet that made this possible
Most model families are built in a different way. You decide you want a 7B model, a 13B model, and a 70B model, then you run three separate training jobs. 3x the compute, 3x the time, three results that aren’t guaranteed to be consistent with each other.
Baidu did something different with ERNIE 5.1. They trained one large model ERNIE 5.0 in a way that contains multiple model sizes within it simultaneously. During training the system randomly varies how many layers are active, how many experts participate in routing, and how many experts activate per token. The result is a single training run that produces an entire family of models at different sizes and compute budgets.
ERNIE 5.1 is extracted from that matrix rather than trained from scratch. Total parameters compressed to roughly one third of ERNIE 5.0. Active parameters at roughly half. Pre-training compute at 6% of what a comparable model trained from scratch would cost. It means Baidu can iterate faster than labs spending full compute on every model. The efficiency compounds into more experiments, faster feedback, and quicker improvements.
Whether that architectural advantage shows up in the benchmarks is exactly what the Search Arena result suggests it does.
Related: ERNIE-Image: Open-Source 8B Text-to-Image Model for Posters, Comics & Structured Generation
The four stage post training pipeline
One of the quiet problems in training large models is what researchers call the seesaw effect. Make the model better at coding and it gets slightly worse at creative writing. Improve math reasoning and instruction following regresses. Every capability gain trades against something else.
Baidu’s approach to ERNIE 5.1 post training attacks this problem directly. Instead of training everything together in one stage, they separate expert training from capability fusion across four sequential stages.
First a unified fine tuning stage establishes baseline instruction following. Then separate expert models for coding, reasoning, and agentic tasks are trained in parallel each one optimized independently without interference from the others. Then a distillation stage pulls all those expert capabilities into one unified model simultaneously. Finally a general reinforcement learning stage handles the capabilities that don’t distill well, creative writing, open ended conversation, tasks with high output diversity.
The result is a model that doesn’t have to compromise between capabilities because those capabilities were never in competition during training. Whether that holds up in practice is what the creative writing claims and the benchmark spread suggest, strong across multiple categories without obvious regressions.
You May Like: Best AI Coding Models for Consumer Hardware
Limitations
ERNIE 5.1 is not open weights. There is no Hugging Face release, so there is no way to run it locally. Access is through Baidu’s own products including the ERNIE website, Baidu AI Studio, and the creative platforms rolling out ERNIE 5.1 integration.
The benchmark situation is also worth being clear about. The Search Arena and text Arena results are independently verified and those are the numbers that matter most for assessing where this model actually stands. The agentic and knowledge benchmarks come from Baidu’s own evaluation setup. Plausible given the Arena results but not independently confirmed.
Creative writing claims are the hardest to evaluate. Approaching Gemini 3.1 Pro on internal creative writing evaluations is a specific claim that requires actually using the model across many creative tasks to verify. Internal evaluations from the model’s own developer are the least reliable signal in the entire release.
Who should care
If you build search products, document retrieval systems, or anything where finding and synthesizing current information matters, ERNIE 5.1’s Search Arena placement is worth paying attention to. 4th globally on an independent leaderboard above Google’s own search model is a signal that deserves more than the coverage it’s getting.
If you work with Chinese language content or serve Chinese-speaking users, this is the most capable model available for that use case by a significant margin.
If you need open weights, local deployment, or hardware you control, this isn’t the model for that. Baidu keeps ERNIE behind their own products and that’s unlikely to change.
The broader point is simpler. Western AI coverage has a blind spot around models that aren’t from OpenAI, Anthropic, Google, or the handful of Chinese labs that release open weights. ERNIE 5.1 sits 13th globally on text Arena and 4th on Search Arena. That’s not a regional result. That’s a global one and it deserves to be treated that way.



{kind=link}