
A 1B model scoring 40.42 on AIME 2025 should not be possible. AIME is the American Invitational Mathematics Examination, the kind of test that filters out most humans who attempt it. Qwen3-0.6B scores 16.25 on the same benchmark. LFM2.5-1.2B, a larger model, scores 31.88. MiniCPM5-1B, at roughly one billion parameters, beats both.
OpenBMB dropped MiniCPM5-1B, the first model in their MiniCPM5 series, and it’s built specifically for the scenarios like on-device deployment, resource-constrained environments, local inference on consumer hardware.
The AIME score is surprising. The telecom agent benchmark is even more surprising. And then there’s the desktop pet. We’ll get to that.
One checkpoint, two personalities
With most models you get the fast version or the reasoning version. MiniCPM5-1B gives you both from the same weights.
Switch enable_thinking to True and the model enters deliberate reasoning mode, working through problems step by step before answering. Switch it off and you get a fast conversational assistant.
Running two separate models on constrained hardware is often not practical. Having one model that adapts to the task without requiring you to manage multiple downloads and contexts is a real convenience.
The recommended settings reflect the difference in what each mode is doing. Think mode runs at temperature 0.9 with top_p 0.95 to give the reasoning process room to explore. No Think mode drops to 0.7 for more predictable, focused responses. Both are sensible defaults and both can be adjusted through standard inference parameters.
The training recipe that explains the numbers
OpenBMB published the full training stack and it’s worth understanding because it explains why MiniCPM5-1B outperforms models of similar or larger size on specific tasks.
The post-training process runs in three stages: supervised fine-tuning, reinforcement learning, and On-Policy Distillation. The SFT stage used 400B tokens total, split between deep-thinking and hybrid-thinking data, establishing the baseline reasoning and chat capabilities. Then RL trained specialized teachers for math, code, closed-book QA, writing, and instruction following separately. OPD then distilled those teachers back into the single release model.
The result of RL plus OPD combined is a 16 point average score improvement over the SFT-only checkpoint, alongside a 29 percentage point drop in responses that hit the maximum token budget. That second number matters as much as the first. A model that reasons efficiently and stops when it has an answer is more useful in production than one that pads responses until it runs out of context. Overlong responses waste compute, slow inference, and often indicate the model is uncertain rather than thorough.
The training data is also fully released alongside the model as Ultra-FineWeb, Ultra-FineWeb-L3, UltraData-Math, and UltraData-SFT-2605 for anyone who wants to study or reproduce the recipe.
Benchmarks
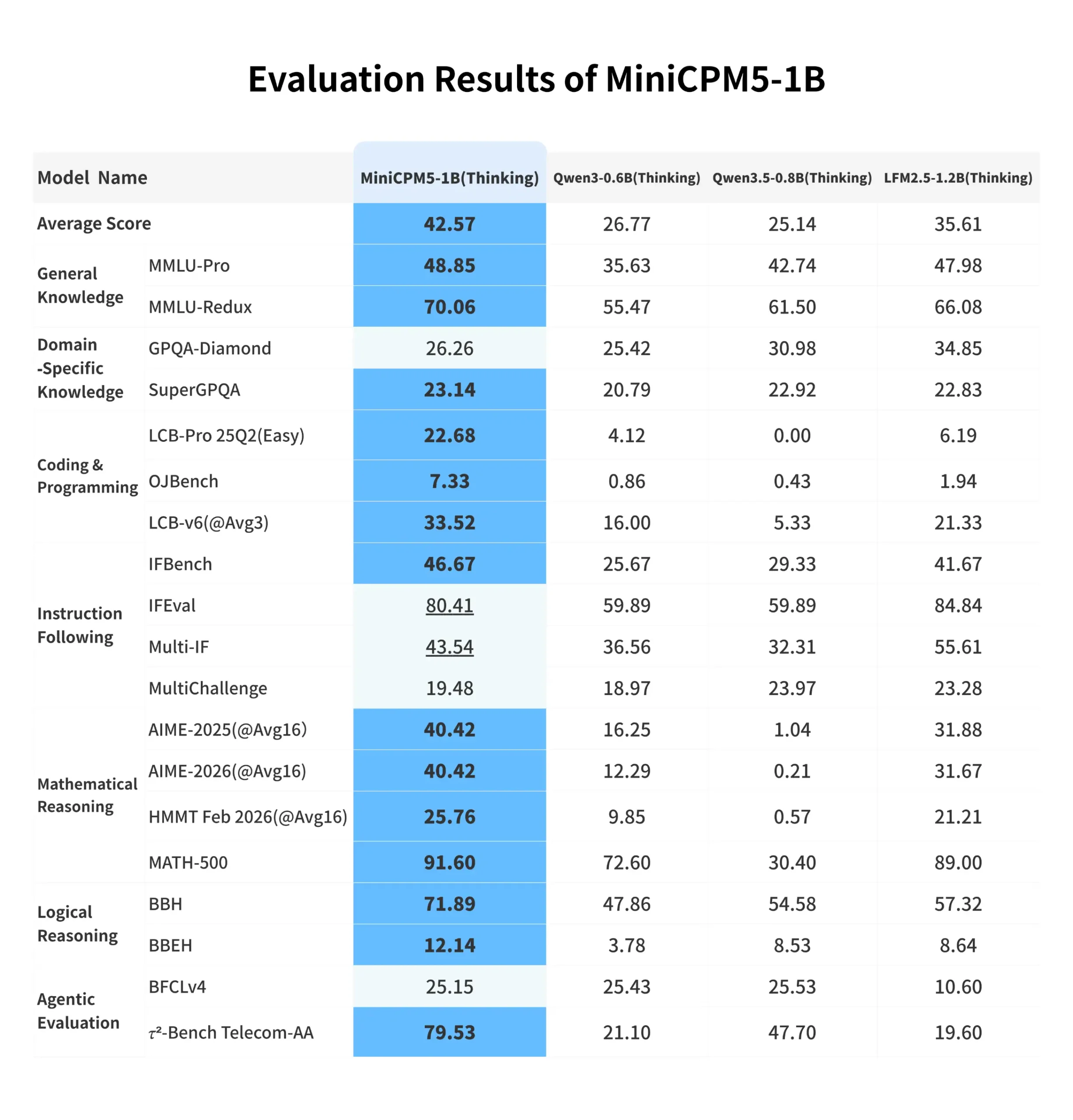
The benchmark that stands out most isn’t AIME. It’s τ2-Bench Telecom at 79.53.
τ2-Bench tests multi-step agentic task completion in realistic enterprise environments, specifically telecom workflows which are notoriously complex and procedural. Qwen3-0.6B scores 21.10 on the same benchmark. LFM2.5-1.2B scores 19.60. MiniCPM5-1B nearly quadruples both of them. That gap is large enough that it’s worth treating as a genuine capability difference rather than benchmark noise.
Here’s a tight comparison across the benchmarks that tell the story:
| Benchmark | MiniCPM5-1B (Thinking) | Qwen3-0.6B | Qwen3.5-0.8B | LFM2.5-1.2B |
|---|---|---|---|---|
| AIME 2025 | 40.42 | 16.25 | 1.04 | 31.88 |
| AIME 2026 | 40.42 | 12.29 | 0.21 | 31.67 |
| MATH-500 | 91.60 | 72.60 | 30.40 | 89.00 |
| τ2-Bench Telecom | 79.53 | 21.10 | 47.70 | 19.60 |
| IFEval | 80.41 | 59.89 | 59.89 | 84.84 |
| BBH | 71.89 | 47.86 | 54.58 | 57.32 |
| LCB-v6 | 33.52 | 16.00 | 5.33 | 21.33 |
All figures from OpenBMB’s evaluation. Self-reported benchmarks should be read with that caveat.
The coding numbers deserves to be noted as well. LCB-Pro Easy at 22.68 against Qwen3-0.6B’s 4.12 and Qwen3.5-0.8B’s flat zero. OJBench at 7.33 against both Qwen models below 1. These are competitive programming benchmarks and the gap at 1B scale is unusually wide.
GPQA-Diamond at 26.26 trails LFM2.5-1.2B’s 34.85, which is the clearest benchmark where a larger model pulls ahead on difficult scientific reasoning.
Related: MiniCPM-V 4.6: The 1.3B Model Running on Your Phone That Challenges Much Larger Rivals
How to run it, and about that desktop pet
MiniCPM5-1B uses standard LlamaForCausalLM architecture which means mainstream inference engines load it directly without custom kernels or model-code forks. Ollama, vLLM, SGLang, llama.cpp, LM Studio, and MLX for Apple Silicon all work out of the box. For tool calling specifically, SGLang is the recommended backend since it handles MiniCPM5’s XML-style tool calls natively through a built-in parser.
The model is on Hugging Face under Apache 2.0, which is as permissive as licenses get.
Now about the desktop pet. OpenBMB ships MiniCPM-Desk-Pet alongside the model, a local desktop companion driven entirely by MiniCPM5-1B running on your own hardware. It supports Apple Silicon, NVIDIA GPU, and CPU paths, integrates with coding agents like Cursor and Claude Code, and supports LoRA persona switching. It’s genuinely unusual to see a serious reasoning model release bundled with something this playful and it says something about who OpenBMB is building for. Not just researchers and enterprise teams. People who want capable AI running locally in whatever form makes sense for them.
If you’re evaluating small models for local deployment, agentic tool use, or constrained inference scenarios, MiniCPM5-1B belongs on your shortlist.



{kind=link}