
For the past year, the open source AI space has been dominated by a familiar narrative. A handful of labs release powerful models, benchmarks circulate on social media, comparisons are drawn with closed systems like GPT & Gemini, and then the noise slowly fades.
But every once in a while, a release stands out not because its loud, but because of who released it and what it signals.
Xiaomi, a company globally recognized for building smartphones at massive scale and more recently expanding into electric vehicles, has quietly open sourced a new large language model called MiMo V2 Flash. There was no flashy launch event. No aggressive marketing push. Just a technical report, model weights, & benchmarks placed in public view.
That alone makes it worth paying attention.
Xiaomi is not a research lab experimenting on the sidelines. It is a technology giant that understands production constraints, cost efficiency, and real world deployment. When a company like this releases an open source foundation model, it is rarely an academic exercise. It is a strategic move.
This article is not about declaring a winner in the AI race. Instead, it explores why MiMo V2 Flash matters, what it brings to the table, how it compares with existing open models, and what its release means for developers, startups, and anyone looking to build AI systems.
Table of contents
What Is MiMo V2 Flash & Why It Matters??
MiMo V2 Flash is Xiaomi’s latest open source foundation language model, built with a strong emphasis on reasoning, coding, and agent based workflows. Xiaomi has focused on efficiency, deployment readiness, and real world usability.
At a time when many open models struggle to balance performance with cost, MiMo V2 Flash takes a different architectural path. It uses a Mixture of Experts design that delivers high intelligence while keeping inference lightweight and fast. This makes it suitable not just for experiments, but for production systems.
Instead of positioning MiMo as a research curiosity, Xiaomi is clearly framing it as infrastructure for developers.
Features of Mimo V2 Flash
| Feature | Details |
|---|---|
| Model Architecture | Mixture of Experts with 309B total parameters and only 15B active per inference |
| Attention Mechanism | Hybrid attention combining sliding window and full global attention |
| Context Length | Supports up to 256K tokens for long multi step workflows |
| Primary Strengths | Reasoning, coding, software engineering, and agentic tasks |
| Thinking Modes | Optional hybrid thinking mode for step by step reasoning or instant responses |
| Performance | Top 2 among open source models on AIME 2025 and GPQA Diamond |
| Coding Ability | Ranked #1 among open source models on SWE Bench Verified and Multilingual |
| Speed | Around 150 tokens per second with optimized inference |
| Cost Efficiency | Extremely low cost per million tokens compared to similar capability models |
| License | MIT licensed, fully open for commercial and production use |
| Availability | Hugging Face, APIs, AI Studio, and open inference frameworks |
Why This Approach Is Different??
Many open models attempt to compete by scaling parameters or mimicking closed systems. MiMo V2 Flash takes a more pragmatic approach. It optimizes for throughput, cost, and reliability, which are the exact constraints developers face when building real products.
By combining long context handling, strong software engineering performance, and low inference cost, MiMo V2 Flash positions itself as a serious alternative for teams that want control over their AI stack without sacrificing capability.
This balance between openness and practicality is what makes MiMo V2 Flash stand out in an increasingly crowded open source AI landscape.
Capabilities of MiMo V2 Flash in Real World Scenarios
According to Xiaomi’s official announcement, MiMo V2 Flash is designed to handle real-world tasks that matter to developers, entrepreneurs, and everyday users. Here’s how it performs across different practical applications:
| Scenario | What MiMo V2 Flash Does | Real-World Use |
|---|---|---|
| Reasoning & Problem Solving | Excels at math, logic, and structured problem solving with a hybrid attention architecture | Can assist in educational tools, scientific research, and automated decision-making |
| Coding & Software Development | Generates functional code, supports multiple programming languages, integrates with coding scaffolds like Claude Code or Cursor | Accelerates software development, creates prototypes, helps debug code, or automates repetitive programming tasks |
| Agentic Tasks | Handles multi-step instructions, tool integrations, and complex workflows | Powers AI assistants, chatbots, search agents, or task automation systems for businesses |
| Long-Context Interactions | Maintains context across hundreds of interactions with a 256k token window | Useful for customer support, multi-turn AI assistants, or collaborative AI environments |
| Multilingual Support | Resolves coding and reasoning tasks across multiple languages | Enables global application development and multilingual educational or productivity tools |
| Everyday Assistant | Provides explanations, drafts content, and helps brainstorm ideas | Acts as a personal AI assistant for knowledge work, creative writing, or task management |
Benchmark Showdown: MiMo V2 Flash, DeepSeek V3.2 & Kimi K2 Thinking
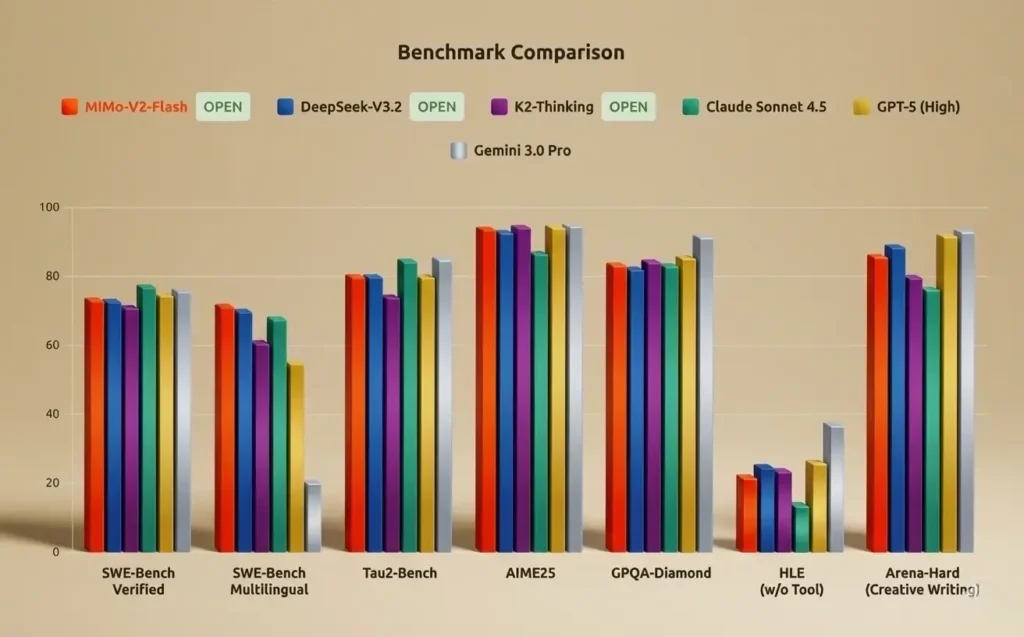
| Benchmark / Task | MiMo V2 Flash | DeepSeek V3.2 (Prod / Speciale) | Kimi K2 Thinking | Refined Technical Notes |
| AIME 2025 | 94.1% | 93.1% / 96.0% | 94.5% / 99.1% | Kimi K2’s high score relies on integrated Python execution for verifiable steps. |
| HMMT Feb 2025 | 84.4% | 92.5% / 99.2% | 89.4% / 95.1% | DeepSeek-Speciale holds the world record for the February 2025 competition. |
| GPQA-Diamond | 83.7% | 79.9% / 82.4% | 84.5% / 85.7% | Kimi leads in scientific reasoning; MiMo is the top-performing small model. |
| MMLU-Pro | 84.9% | 85.0% | 84.6% | Statistical parity (within 1%) across all three leading models. |
| SWE-Bench Verified | 73.4% | 73.1% | 71.3% | MiMo V2 Flash is the most efficient open-source model for software engineering. |
| SWE-Bench Multilingual | 71.7% | 70.2% | 61.1% | MiMo maintains a significant lead in non-English coding environments. |
| LiveCodeBench v6 | 80.6% | 83.3% | 83.1% | DeepSeek and Kimi are essentially tied for competitive programming leadership. |
| Terminal Bench 2.0 | 38.5% | 46.4% | 35.7% | DeepSeek V3.2 is currently the dominant CLI and terminal-based agent. |
| τ²-Bench (Agentic) | 80.3% | 80.3% | 74.3% | MiMo and DeepSeek share the top spot for general-purpose agentic reliability. |
| Context Window | 256k tokens | 128k tokens | 256k tokens | Correction: DeepSeek V3.2 officially supports 128k tokens. |
| Active Parameters | 15B | 37B | 32B | MiMo achieves similar performance with less than half the active parameters. |
| Price (1M In/Out) | $0.1 / $0.3 | $0.28 / $0.42 | $0.60 / $2.50 | MiMo is the value leader; Kimi is optimized for premium reasoning tasks. |
Also Read: Developers Are Quietly Switching to These Open-Source Tools for 2026
How MiMo Challenges DeepSeek & Other Open Models??
One of MiMo’s biggest advantages lies in its efficiency and compute footprint. With only 15B active parameters, it achieves performance comparable to DeepSeek’s 37B active parameters, making it significantly lighter while delivering top-tier results in benchmarks like SWE-Bench Verified & τ²-Bench.
The context window further distinguishes MiMo. Supporting up to 256,000 tokens, it doubles the context length of DeepSeek’s 128,000-token window, enabling extended multi-step reasoning, complex tool use, and long agent interactions.
In terms of coding and agentic capabilities, MiMo performs exceptionally well in multilingual coding benchmarks and general tool-use tasks, demonstrating versatility that rivals more resource-intensive models. Tasks like generating functional HTML with one click or handling complex software problems showcase its practical utility for developers.
Finally, the price-to-performance ratio makes MiMo highly accessible. At $0.1 per million input tokens and $0.3 per million output tokens, it is far more cost-effective than both DeepSeek and Kimi, lowering the barrier for startups and entrepreneurs aiming to integrate high-quality LLMs into their products.
In real-world scenarios, these advantages mean developers can build powerful AI-driven solutions, experiment with agentic workflows, and scale complex projects without the heavy infrastructure costs typically associated with advanced LLMs.
License and Accessibility
MiMo V2 Flash is fully open-source, available under Xiaomi’s official MIT license. This means developers, startups, and researchers can freely access, modify, and integrate the model into their projects.
Use Cases and Applications
Xiaomi highlights its capabilities across multiple scenarios:
- Coding Assistant: MiMo can handle complex programming tasks, generate functional code, debug, and even support multi-language coding workflows. Its performance on SWE-Bench Verified and Multilingual benchmarks shows it excels in both English and non-English coding tasks.
- Reasoning and Problem Solving: From solving math competitions like AIME 2025 to scientific knowledge tests like GPQA-Diamond, MiMo V2 Flash provides accurate reasoning for analytical tasks.
- General AI Assistant: It can act as a personal assistant, help draft documents, summarize information, or provide context-aware advice for projects and workflows.
- Agentic and Tool-Integrated Workflows: MiMo supports agentic scenarios, allowing developers to create AI tools that interact with other systems, APIs, and workflows automatically. Its ultra-long 256k context window ensures it can manage complex, multi-step tasks efficiently.
From building AI-powered productivity apps to designing custom coding assistants, MiMo V2 Flash opens the door for startups and innovators to leverage cutting-edge AI capabilities without the high costs or restrictive licenses of proprietary models.
Also Read: 12 Free Desktop Apps I Wish I Discovered Sooner: Must-Haves for 2026
Conclusion
MiMo V2 Flash marks a significant milestone in the open-source AI landscape. Xiaomi has delivered a model that combines blazing-fast performance, cost-efficiency, and versatility for reasoning, coding, and agentic workflows. Its strong benchmark performance, especially compared to DeepSeek V3.2 and Kimi K2 Thinking, demonstrates that open-source models can rival and in some areas even surpass top-tier proprietary alternatives.



{kind=link}