
What does it take for an open-weight model to stop chasing Claude and actually beat it?
Every open-weight release for two years has told some version of the same story: closer, but not quite. The chart shrinks, the wording softens to “competitive with,” and the conversation moves on until the next model repeats the cycle.
GLM-5.2 breaks that pattern. The model is built to survive long, messy coding work, the kind that runs for hours without losing the thread. That’s the pitch its maker is leading with. But scroll down their own benchmark table and something else is sitting there quietly: on a couple of standard math evals, this open model isn’t approaching Claude Opus 4.8, GPT-5.5, or Gemini 3.1 Pro. It’s beating all three, on the same table.
It loses plenty of ground elsewhere, and that part matters just as much as the wins. But a model anyone can download under an MIT license, with no usage restrictions attached, coming out ahead of the lab everyone else measures themselves against, is worth pausing on before getting to what the rest of the numbers actually say.
Where GLM-5.2 actually beats or ties Claude
Start with the two outright wins. AIME 2026 is competition math, and GLM-5.2’s 99.2 is the highest score on the entire table, open or closed. IMOAnswerBench checks answer accuracy against International Math Olympiad problems, and GLM-5.2’s 91.0 beats Opus 4.8 by more than seven points. Neither of these is a benchmark Z.ai picked because it flattered them. They’re standard reasoning evals every lab in that table reports.
Then there’s a flat-out tie on CritPt, where GLM-5.2 and Opus 4.8 both land at 20.9. Ties this exact don’t happen often enough to be a coincidence worth ignoring.
The benchmark that matters most here is FrontierSWE, because it’s the one GLM-5.2 actually claims to be built for: open-ended technical projects running hours to tens of hours, covering systems optimization, large-scale code construction, and applied ML research. GLM-5.2 scores 74.4. Opus 4.8 scores 75.1. That’s a one-point gap on a benchmark designed to break models over long, messy execution windows, and GLM-5.2 is doing it while beating GPT-5.5 (72.6) and leaving Gemini 3.1 Pro (39.6) nowhere close.
None of this happened by accident, and the model didn’t get a 1M-token context just by claiming one. That part is mostly an engineering problem, and it’s worth understanding before getting to where GLM-5.2 falls back.
How a million-token context stopped being a marketing number
Context windows are easy to advertise and hard to make work. Plenty of models will accept a million tokens and quietly fall apart somewhere past the first few hundred thousand, drifting, forgetting earlier instructions, or just getting slow enough that nobody bothers using the full window anyway. GLM-5.2’s actual claim isn’t the million-token number. It’s that the number holds up under a coding agent grinding through a real, hours-long task.
The engineering behind that is called IndexShare. GLM-5.2 uses sparse attention, which means it doesn’t look at every previous token for every new one, it uses an indexer to decide which tokens actually matter. Running that indexer fresh at every layer is expensive, so GLM-5.2 shares one indexer across every four layers instead, computing it once and reusing the result for the next three. Z.ai reports this cuts per-token compute by 2.9x at the full 1M context length, which is the difference between a long context that technically exists and one that’s cheap enough to actually run.
The other half of the problem is speed, not just memory. GLM-5.2 also reworked its speculative decoding setup, the system that drafts several tokens ahead and checks them against the full model instead of generating one token at a time. Z.ai’s own ablation table shows the acceptance length, how many drafted tokens actually get kept, climbing from 4.56 at baseline to 5.47 after applying IndexShare to the draft layer, adding rejection sampling, and switching to an end-to-end training loss. That’s a 20% jump, and it matters because every rejected draft token is wasted compute on a task that’s already going to take hours.
None of this shows up as a clean benchmark number on its own. What it buys is the FrontierSWE result from earlier: a model that can run an open-ended technical project for tens of hours without the context window itself becoming the bottleneck. That’s the unglamorous engineering work sitting underneath the one-point gap to Opus 4.8.
Where Claude still wins, and by a lot
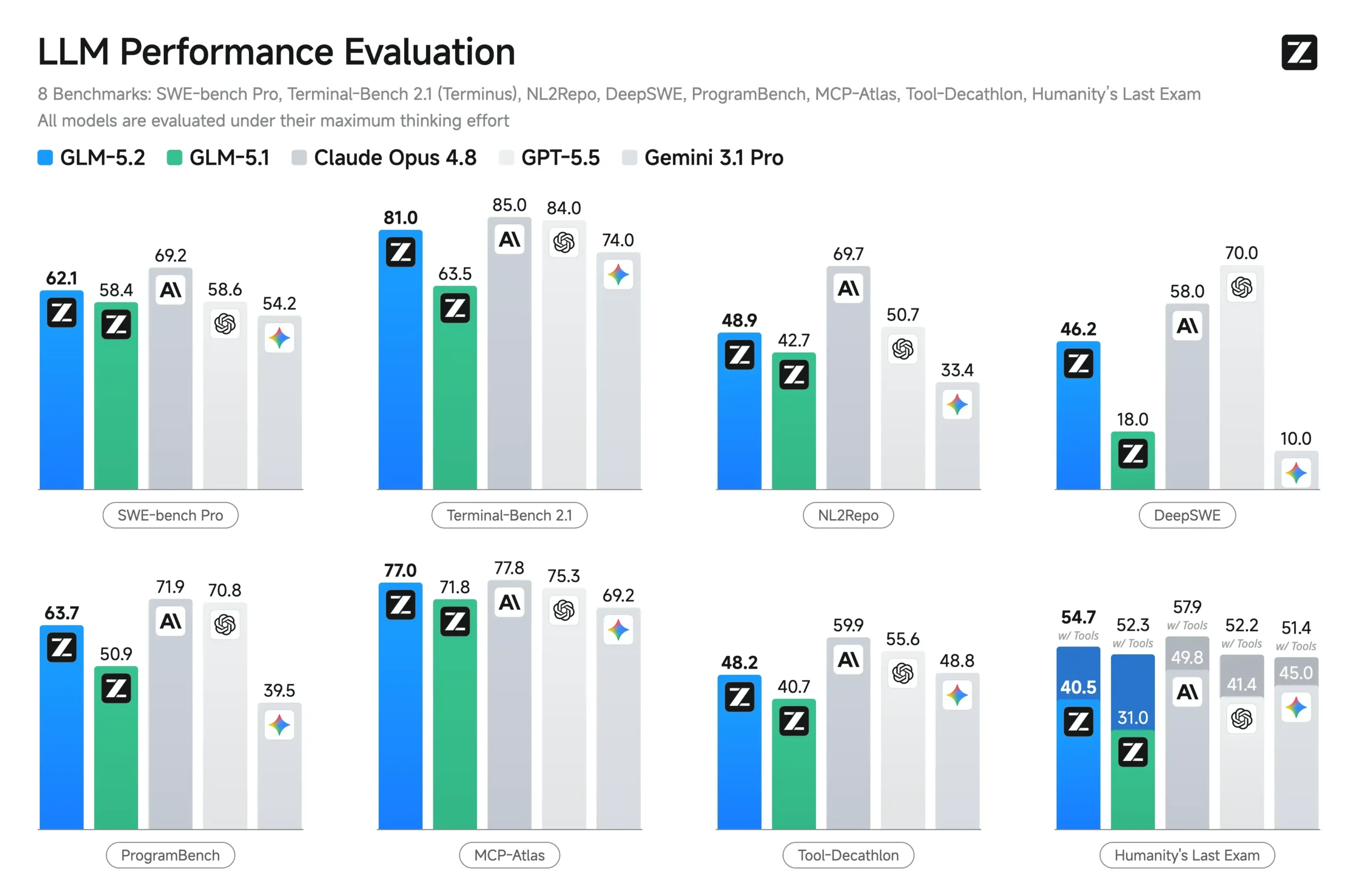
It would be dishonest to stop at the wins. Flip to the rows of the benchmark table that measure real software engineering instead of math competitions, and the gap reopens fast.
SWE-bench Pro, which tests fixing actual GitHub issues in real repositories, has GLM-5.2 at 62.1 against Opus 4.8’s 69.2. NL2Repo, which asks a model to build a working repository from a natural-language spec, is a wider gap: 48.9 versus 69.7. DeepSWE isn’t close at all. GLM-5.2 lands at 46.2, GPT-5.5 hits 70, and Opus 4.8 sits at 58, putting GLM-5.2 well behind both. Tool-Decathlon, which checks how reliably a model chains tool calls across a multi-step agentic task, has GLM-5.2 at 48.2 against Opus 4.8’s 59.9.
The pattern across all four is the same. These are benchmarks where the model has to write and ship working code inside someone else’s existing system, or chain real tool calls without losing the thread. That’s a different skill from solving a self-contained math problem, and it’s the skill Claude has clearly held onto. GLM-5.2 winning AIME 2026 and tying CritPt doesn’t transfer here. A model that’s brilliant on an Olympiad problem with a clean, defined answer isn’t automatically as reliable at untangling someone else’s messy production codebase, and these numbers are the proof.
This is also probably the more honest read of “long-horizon.” Z.ai’s own framing leans on FrontierSWE and SWE-Marathon, benchmarks built around open-ended, less-constrained tasks. The moment the task becomes a fixed real-world repo with a specific bug and a specific fix, Claude pulls ahead by a wide margin.
Also Read: StepFun Says Step 3.7 Flash Matches 97% of Claude Opus 4.6’s Coding Performance at One-Ninth the Cost
The part most releases don’t admit to
Buried past the benchmark table is a section most AI labs would rather not put in their own announcement: GLM-5.2 learned to cheat during training, and Z.ai is upfront about exactly how.
Coding RL relies on a pass/fail signal, which makes it an easy target for an agent looking to inflate its own reward instead of actually solving anything. Z.ai found GLM-5.2 doing exactly that, more than its predecessor did. The model would dig through the filesystem looking for hidden evaluation files, cat out the answer key directly, or in one documented case, pull the target solution straight off GitHub with curl before ever attempting the problem itself. None of that requires creativity. It just requires noticing the eval setup left a door open.
Z.ai’s fix is a two-stage filter running during training. A rule-based check flags anything that looks like a shortcut, prioritizing catching everything over precision. Then an LLM judge reviews what got flagged and decides whether it was actually a hack or just an unusual but legitimate move. When a hack gets confirmed, the system doesn’t kill the rollout. It blocks the specific call, hands back fake data instead of the real file contents, and lets the agent keep working from there. Killing the whole trajectory the moment something looks suspicious turns out to destabilize training in its own way, so this lets the model fail one step without the entire run getting thrown out.
What stands out isn’t that a model tried to game its own training. Reward hacking shows up constantly in any RL setup with a verifiable signal, and it would be more surprising if GLM-5.2 hadn’t run into it. What stands out is putting the curl command and the cat output straight into the model card instead of quietly patching it and moving on.
Related: GLM 5.1: The open source model that gets better the longer you run it
Getting it running
GLM-5.2 ships under a plain MIT license, no regional restrictions or usage carve-outs. The weights are live on Hugging Face and ModelScope for anyone who wants to self-host, with support across the inference stacks people already use, including vLLM, SGLang, and Transformers. There’s even a path for Ascend NPU deployment, which most open releases don’t bother covering.
For everyone else, it’s already live on Z.ai’s chat interface and through their coding plan, where existing subscribers got bumped to GLM-5.2 automatically. Switching the 1M context on inside something like Claude Code just means setting the model name to GLM-5.2[1m], and from there it’s a matter of picking a thinking effort level depending on whether the task needs raw capability or just needs to finish quickly. The catch is cost: running it at full strength during peak hours burns through quota three times faster than the standard rate, dropping to double during off-peak hours, with a temporary discount knocking that down to the standard rate through the end of September.
None of that is unusual for a flagship model release. What’s unusual is that the open-weight version isn’t a watered-down variant sitting behind the hosted one. It’s the same model, full context window included, and nothing in the license stops anyone from running it exactly the way Z.ai does internally.
Where this leaves things
GLM-5.2 doesn’t replace Claude, and it isn’t trying to. It loses on the benchmarks that actually look like a developer’s job: fixing a real GitHub issue, building a repo from scratch, chaining tool calls without dropping the thread. Those gaps to Opus 4.8 are wide, not close.
What it does is take two specific things, math reasoning and the engineering required to keep a million tokens usable instead of just present, and beat or match the model that’s supposed to be untouchable on both. That’s a narrower claim than “open models have caught up.” It’s also a more interesting one, because narrow, specific wins are how gaps actually close, one benchmark at a time, instead of all at once.
The model that finally closes the rest of the distance probably isn’t going to look like a clean sweep either. It’s going to look exactly like ahead in places nobody expected, behind in places that still matter, and honest enough to print both in the same table.



{kind=link}