
$0.19 vs $1.76. That’s the per-task cost of running Step 3.7 Flash with Advisor Mode enabled versus Claude Opus 4.6 on SWE-Bench Verified. The Flash model scores 76.3% to Opus 4.6’s 78.7%. Two percentage points of difference. Nine times cheaper to get there.
For anyone building agentic coding workflows at scale that math changes the decision about which model actually belongs in production. Frontier performance has been getting cheaper for a while but this is a specific, benchmarked claim with a specific cost figure attached.
198B total, 11B doing the work
Step 3.7 Flash is a 198B parameter sparse MoE model with 11B parameters actually activate per token at inference time.
Only the relevant experts fire for any given input, which means the compute cost per token looks much closer to an 11B dense model than a 198B one. The result is throughput of up to 400 tokens per second, which is genuinely fast for a model with this capability profile.
The vision side adds a 1.8B parameter encoder on top of the language backbone, giving it native image understanding without the full multimodal tax that some larger models pay. It handles UI wireframes, charts, dense documents, and natural scenes, then acts on what it sees by writing code or calling tools directly.
Context window is 256k tokens with three selectable reasoning levels, low, medium, and high, so you can tune the speed and cost tradeoff per request depending on what the task actually needs.
The trick that makes the cost number possible
Advisor Mode is the specific mechanism behind that $0.19 figure.
The basic problem with long agentic runs is that most of the work is routine. Tool calls, reading results, iterating on straightforward steps. You don’t need a frontier model for that. But occasionally the agent hits a genuinely hard decision point, a planning step that could send the whole trajectory wrong, or a recovery from repeated failures that requires real judgment. That’s where the small model falls short.
Advisor Mode keeps Step 3.7 Flash in control of the full run. It calls tools, reads results, and iterates end to end. But at specific inflection points where its own judgment isn’t sufficient, it consults a larger advisor model and then continues executing on that guidance. The expensive model gets used only where it actually matters.
StepFun describes this as their implementation of the executor-advisor strategy that Anthropic has written about. The small model stays cheap through most of the run. The advisor cost gets amortized across many steps rather than paid on every token. The result is 97% of Opus 4.6’s performance at roughly one-ninth the cost per task on SWE-Bench Verified.
Where it leads the benchmarks
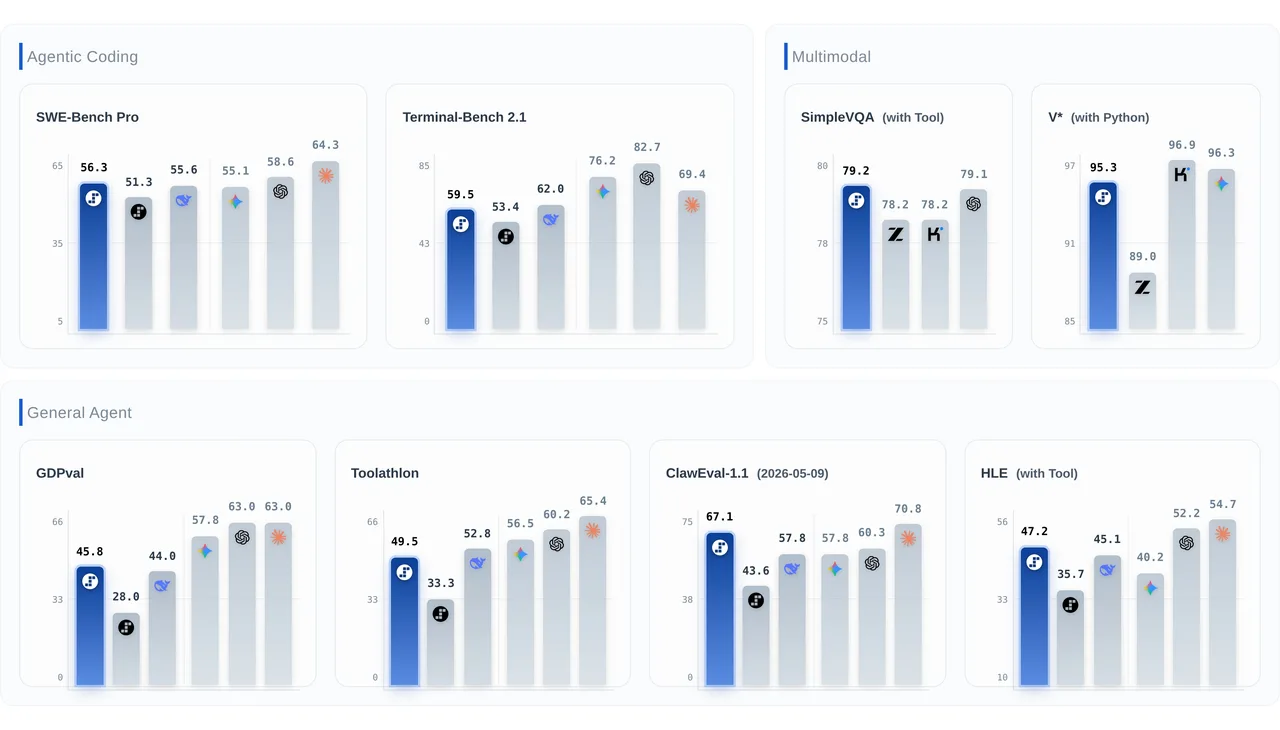
ClawEval-1.1 is the one to notice first. Step 3.7 Flash scores 67.1, which leads the entire benchmark by a meaningful margin. The next closest competitor sits at 59.8. ClawEval tests resistance to adversarial traps and instruction adherence across multi-turn orchestration, which is exactly the kind of reliability that matters when you’re running agents autonomously across long workflows.
The multimodal numbers are strong too. SimpleVQA with search tools hits 79.2, first place in that category, ahead of GPT 5.5 at 79.1 and GLM 5V Turbo at 78.2. V* with Python tools reaches 95.3, competitive with Kimi K2.6 at 96.9 and Gemini 3 Flash at 96.3. These are Flash-tier results matching Pro-tier models on visual tasks.
Search benchmarks tell a similar story. BrowseComp at 75.8%, DeepSearchQA F1 at 92.8% comparable to Kimi K2.6 which runs at 1T total parameters and 32B active. ResearchRubrics at 71.7%, ahead of GPT 5.5 at 61.5% and close to Claude Opus 4.7 at 73.9%.
The cross-harness coding results are also worth noting. On StepFun’s internal Step-SWE-Bench across six agent scaffolds including Claude Code, KiloCode, OpenClaw, and RooCode, Step 3.7 Flash averages 67.08% versus Step 3.5 Flash’s 56.5%. The consistency across scaffolds matters as much as the average. A model that performs well on one harness and collapses on another isn’t actually reliable for production use.
All benchmark numbers are from StepFun’s own evaluation unless otherwise noted. Self-reported results should be read with that point.
Where frontier models still win
Terminal-Bench 2.1 is the clearest gap. Step 3.7 Flash scores 59.5 against GPT 5.5 at 82.7 and Gemini 3.5 Flash at 76.2. That’s not a close race. For workflows that depend heavily on terminal interaction and complex command execution, this model isn’t the right choice at the moment.
GDPval, which tests performance across 44 professional occupations, shows Step 3.7 Flash at 45.8% against GPT 5.5 and Claude Opus 4.7 both at 63%. That’s a significant gap for general professional task coverage.
HLE with tools at 47.2% trails Claude Opus 4.7 at 54.7% and GPT 5.5 at 52.2%. For the hardest reasoning tasks with tool use, frontier models still have a clear edge.
SWE-Bench Verified at 76.5% is competitive but Claude Opus 4.7 sits at 87.6% which is a real difference for complex software engineering tasks where accuracy matters more than throughput.
Step 3.7 Flash is a specialist that excels at specific agentic tasks, particularly tool orchestration, visual understanding, and search-heavy workflows, rather than a model that wins across every dimension. The cost efficiency story holds most strongly for those specific use cases.
You May Like: ZAYA1-8B Matches DeepSeek-R1 on Math with Less Than 1B Active Parameters.
Who this is for and how to run it
If you’re building agentic workflows where tool orchestration reliability and cost per task matter more than raw benchmark ceiling, Step 3.7 Flash is worth serious evaluation. The ClawEval lead and the Advisor Mode cost profile are both genuinely differentiated.
If you need top Terminal-Bench performance or maximum general professional coverage, the gaps are noticable enough that frontier models remain the better choice.
The model is available via StepFun’s API on platform.stepfun.ai globally and platform.stepfun.com for China, as well as OpenRouter and NVIDIA NIM. Local deployment requires at least 128GB unified memory, workable on Mac Studio, NVIDIA DGX Station, or AMD Ryzen AI Max+ 395 systems. Standard inference backends are supported including vLLM, SGLang, and llama.cpp. License is Apache 2.0.



{kind=link}