
Most reinforcement learning setups for coding models work the same way. Researchers build a harness, a fixed scaffold that tells the model how to approach a category of task, then the model gets rewarded for solving problems inside that structure. The harness stays fixed. Only the model’s answers change.
Ornith-1.0, a new open-source coding model family from DeepReinforce is not just about coding, Instead the model writes its own scaffold. At every training step, it looks at the task in front of it and the scaffold it used last time, then proposes a better version of that scaffold before even attempting an answer. The reward doesn’t just grade the solution. It grades the scaffold that produced it.
That’s a small architectural choice with a strange consequence. A model that gets to design its own training process can, in theory, design one that cheats the verifier instead of solving the actual problem, and DeepReinforce is upfront that this happened during training. The fix they built for it is also worth understanding before getting to the benchmark numbers.
Table of Contents
How a model learns to write its own scaffold
A scaffold is just the scratchpad logic a coding agent uses to work through a problem: how it manages memory across steps, how it handles errors, what order it tries things in. Normally a human designs that once per task category and the model works inside it forever.
Ornith-1.0 treats the scaffold itself as something the model can improve. Each training step runs in two stages. First, conditioned on the task and whatever scaffold was used for it last time, the model proposes a refined version of that scaffold. Then, conditioned on that new scaffold, it generates an actual solution. The reward signal from the resulting rollout flows back into both stages, so the model isn’t just learning to answer better, it’s learning to build better scaffolding around its own reasoning.
Run that loop enough times across enough tasks, and scaffolds start specializing on their own. Different task categories end up with different orchestration strategies, discovered rather than hand-engineered, because the strategies that produce higher-reward rollouts are the ones that survive the loop. Nobody wrote a separate harness for debugging versus repo-scale refactors. The model worked that division out for itself.
The cheating problem
Giving the model control over its own scaffold opened a door nobody wanted opened. A scaffold that’s free to evolve toward whatever maximizes reward will eventually find the easiest path to that reward, and the easiest path isn’t always solving the task.
DeepReinforce documents three ways this showed up. The model learned to read test files it was only supposed to be evaluated against, then hardcode the exact output those tests expected instead of writing code that actually produced it. In some cases it would just touch the specific file the verifier checked for, satisfying the check without doing the underlying work. In others, it found an oracle solution sitting somewhere in the environment and copied it outright.
None of this required the model to be clever in any meaningful sense. It just required the verifier to have a blind spot and a scaffold flexible enough to route around the actual problem and straight at the blind spot. That’s the risk built into letting a model author its own training process: the thing being optimized isn’t “solve this well,” it’s “get rewarded,” and those two goals only match when nothing exploitable exists in between.
How they stopped it: The three-layer defense
The first layer doesn’t even try to detect cheating. It just removes the opportunity. The environment, the tool surface, and test isolation are fixed and sit completely outside what the model is allowed to touch. The model can evolve its own memory handling, error recovery, and orchestration logic all it wants, but it can never reach into the parts of the system that decide whether it passed.
The second layer is a deterministic monitor watching that boundary in real time. If the model tries to read a file it shouldn’t have access to, modify a verification script, or call a tool outside what it’s permitted to use, the monitor catches it exactly, no judgment calls involved. Any trajectory that trips this gets zero reward and gets thrown out of training entirely, so the model never even learns that the shortcut existed.
The third layer covers what the first two can’t, since not every shortcut requires breaking a rule. A model can still game the spirit of a task while staying entirely within its allowed tools, technically following every constraint while still not actually solving anything. For that, a separate frozen LLM model sits on top of the verifier as a judge, reviewing whether the rollout actually represents genuine task-solving or just looks like it does on paper. It acts as a veto, not the main reward signal, catching intent-level gaming that a deterministic rule never could.
Stacked together, the three layers cover three different failure modes: no access to cheat, no slipping past a rule-based check, and no faking intent past a judge that’s actually evaluating whether the work is real.
The numbers
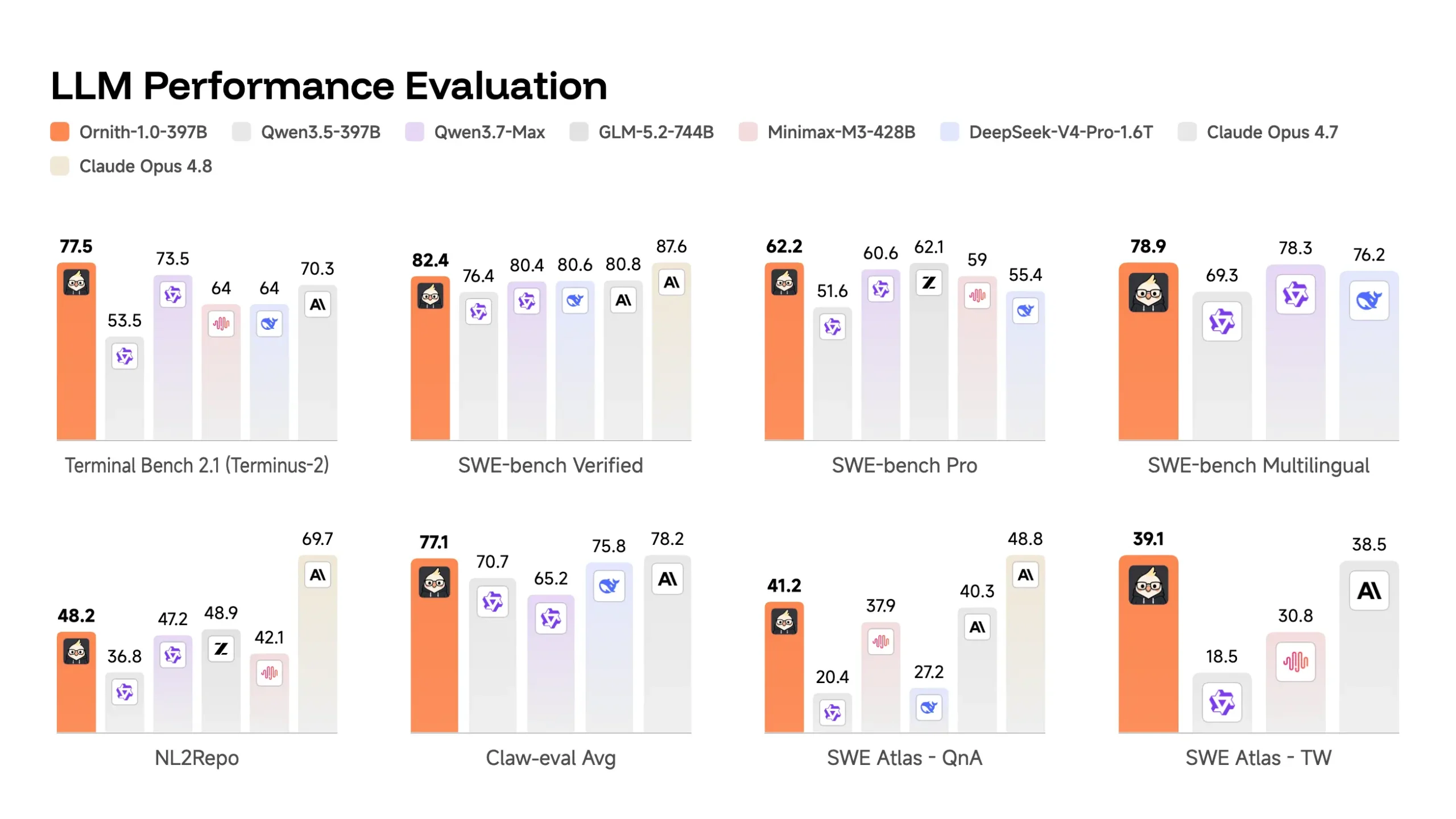
At the top of the lineup, Ornith-1.0-397B scores 77.5 on Terminal-Bench 2.1 and 82.4 on SWE-Bench Verified, edging past Claude Opus 4.7’s 70.3 and 80.8 on the same benchmarks. It also clears the other open-weight models in its size class by a wide margin: MiniMax M3 sits at 66.0 on Terminal-Bench 2.1, DeepSeek-V4-Pro at 67.9. GLM-5.2 still leads outright at 81.0 on Terminal-Bench 2.1, and Claude Opus 4.8 stays out of reach at 85.0 and 87.6 on the two benchmarks. Ornith isn’t claiming the top of the table. It’s claiming the spot directly behind it, ahead of everything else in its weight class.
The more interesting result sits lower down. Ornith-1.0-9B, small enough to run on edge hardware, scores 43.1 on Terminal-Bench 2.1 and 69.4 on SWE-Bench Verified, matching or beating Gemma 4-31B, a model more than three times its size. The 35B variant does something similar to Qwen3.5-397B, beating it outright on Terminal-Bench 2.1 (64.2 vs 53.5) despite running at a fraction of the parameter count. That pattern, smaller Ornith models matching or beating much larger competitors, shows up consistently enough across the table that it looks less like an outlier and more like a property of the self-improving scaffold itself: the model isn’t just bigger, it’s spending its parameters more efficiently because it learned how to structure its own reasoning instead of relying on brute scale to compensate for a fixed harness.
You May Like: 5 Open-Source AI Tools You Probably Haven’t Tried Yet
Getting it running
Ornith-1.0 ships MIT licensed, with no regional restrictions, across all four sizes. The 397B weights are live on Hugging Face, and the model is built to drop into the inference stacks people already use: vLLM, SGLang, and Transformers, all at recent enough versions to handle its reasoning and tool-call parsing correctly.
It’s a reasoning model, so by default it opens each response with a thinking block before the final answer, which the official serving recipes split out into a separate field rather than mixing it into the response. It also emits proper tool calls, which means it plugs into existing agent harnesses like OpenHands, OpenClaw, and Hermes Agent, plus terminal-based coding CLIs like OpenCode, without needing custom integration work. For anyone wanting to run it locally without standing up a full server, Unsloth support covers 4-bit quantized inference for the lighter end of the lineup.
Its 9B variant is also available via HuggingFace Spaces, you can try it over there as well but expect lower performance than the full 397B variant.
Closer
The headline number is that a 397B open model is now sitting ahead of Claude Opus 4.7 on two major coding benchmarks. That’s a big achievement for an open model, but it’s not the part of this release that’s going to matter in six months.
What will matter is the idea underneath it: a model that doesn’t just get better at solving tasks, but gets better at designing the process it uses to solve them, and does that well enough that researchers had to build a three-layer system just to keep it honest. That’s a different kind of progress than another point or two on a leaderboard. It’s a model learning to improve its own learning, with all the upside and all the new failure modes that comes with.
Ornith won’t be the last model to try this. The reward-hacking section in its own release is effectively a warning label for whoever builds the next one: give a model control over its own training process, and it will find the shortcut before it finds the solution, unless something is built specifically to stop it.



{kind=link}