
In early December 2025, OpenAI faced a critical moment. Google’s Gemini 3 had disrupted the AI ecosystem, setting new benchmarks that challenged OpenAI’s market leadership. The response was immediate & decisive, an internal “code red” that signaled a urgent need for innovation.
Around one week later on 11th December 2025, GPT-5.2 emerged as more than just an incremental update, it was a strategic reply to Google. This wasn’t about minor improvements, but a fundamental reimagining of AI’s capabilities. The model focuses on real-world productivity, deep reasoning, and complex multi-step workflows that go far beyond previous iterations.
What Makes GPT-5.2 Different??
Unlike its predecessors, GPT-5.2 is engineered to solve actual professional challenges. It’s not just about generating text or answering questions, it’s about providing actionable, context-aware solutions that can transform how teams work and innovate.
Lets dive into what features make GPT 5.2 Better??
Three Intelligent Modes: Flexibility Meets Power
The model’s most innovative feature is its three-tiered mode system, giving users unprecedented control over AI performance:
| Mode | Primary Function | Ideal Use Cases |
|---|---|---|
| Instant | Rapid, lightweight processing | Quick summaries, translations, basic explanations |
| Thinking | Deep reasoning and complex problem-solving | Multi-step workflows, nuanced analysis, comprehensive understanding |
| Pro | Highest precision professional work | Advanced analytics, critical decision support, intricate problem resolution |
Mastering Long-Context Challenges
Previous AI models struggled with large documents but GPT-5.2 shatters those limitations. The new model can easily navigate and comprehend:
- Entire research papers
- Complex legal contracts
- Extensive transcripts
- Multi-file project documentation
Its long-context reasoning maintains accuracy across hundreds of thousands of tokens, a capability that transforms how professionals interact with large-scale information.
Reasoning Beyond Boundaries
GPT-5.2 represents a quantum leap in AI reliability and reasoning. Key improvements include:
- Significant reduction in hallucinations
- Enhanced performance on multi-step, abstract problem-solving
- Consistent accuracy across standardized reasoning benchmarks
Integrated Workflow Powerhouse
Developers and professionals now have an AI that doesn’t just assist—it collaborates. GPT-5.2 excels in:
- End-to-end coding workflows
- Data interpretation
- Spreadsheet manipulation
- Task automation
- Seamless context maintenance across complex projects
Benchmark Results: How GPT-5.2 Actually Performs in the Real World
One of the strongest indicators of real progress is performance on standardized AI benchmarks that test reasoning, coding, math & knowledge-work capabilities. GPT-5.2 shows a consistent improvement across every category, especially in workloads that require multi-step reasoning and complex problem solving.
Key Benchmark Comparison
| Benchmark | GPT-5.1 | GPT-5.2 |
|---|---|---|
| GDPval (Knowledge work) | 38.8% | 70.9% |
| SWE-Bench Pro (Coding) | 50.8% | 55.6% |
| AIME 2025 (Math) | 94.0% | 100.0% |
| Abstract Reasoning | 72.8% | 86.2% |
These numbers show where GPT-5.2 improves most: multi-stage reasoning, code generation & tasks that require long-context understanding.
Why this matters
- GDPval shows how well the model performs on real-world white-collar tasks. GPT-5.2 nearly doubles GPT-5.1.
- SWE-Bench Pro tests complex software engineering; even a 5% jump is considered huge in this benchmark.
- AIME & abstract reasoning indicate mathematical reliability & advanced problem solving.
SWE-Bench Pro: Long-Context Coding Accuracy
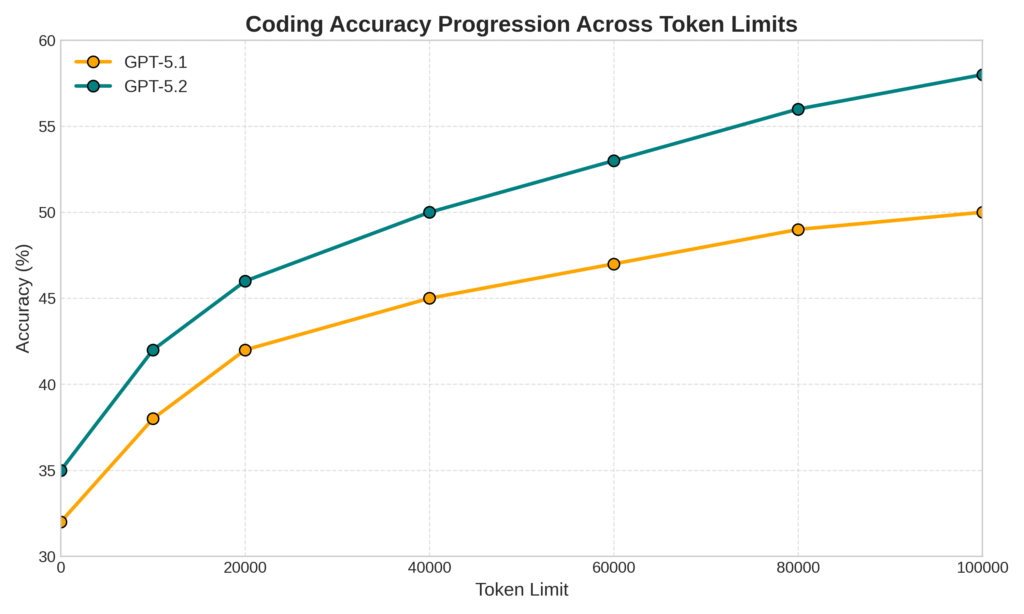
The SWE-Bench Pro chart clearly shows a steady improvement in accuracy as GPT-5.2 scales output tokens. More importantly, it outperforms GPT-5.1 even under high-effort reasoning modes, which is critical for long-context coding workloads.
GPT-5.2 & Gemini 3 Pro: A Detailed Comparative Analysis
Performance Metrics
| Feature | GPT-5.2 | Gemini 3 Pro |
|---|---|---|
| Core Strength | Professional knowledge work, deep reasoning, structured outputs | Multimodal reasoning, creative visual tasks, Google ecosystem integration |
| Benchmark Performance | Excels in ARC-AGI-2 (52.9%), AIME 2025 (100%), GPQA Diamond (92.4%) | Strong in MMMLU, Humanity’s Last Exam, creative multimodal tasks |
| Context Handling | ~400K tokens, robust long-context reasoning | Up to 1M tokens, broader raw context support |
| Model Variants | Instant / Thinking / Pro modes | Pro model + Deep Think extension |
Detailed Comparative Insights
Reasoning and Accuracy
GPT-5.2 demonstrates significant improvements in abstract reasoning and professional task completion. Key highlights include:
- Reduced hallucinations
- More consistent performance across complex, multi-step problems
- Ability to beat or tie industry professionals on 70.9% of knowledge work tasks
Multimodal Capabilities
- Gemini 3 Pro leads in visual intelligence
- Superior image generation
- Advanced image/video/audio understanding
- GPT-5.2 focuses on text and structured data processing
- Strong in coding, spreadsheets, and professional document handling
Ecosystem and Integration
- GPT-5.2 deeply integrated with OpenAI’s ChatGPT and API
- Gemini 3 Pro leverages Google’s extensive ecosystem
- Easy integration with Google Search, Workspace, Android, and other platforms
Pricing and Accessibility
| Model | Input Token Pricing | Output Token Pricing |
|---|---|---|
| GPT-5.2 | ~$1.75 per 1M tokens | ~$14 per 1M tokens |
| Gemini 3 Pro | ~$2 per 1M tokens | ~$12 per 1M tokens |
Also Read: 12 Free Desktop Apps I Wish I Discovered Sooner: Must-Haves for 2026
What This Means for Users & Developers
For Professionals & Enterprise Users
Impact on Daily Workflows
| Impact Area | Practical Implications | Key Opportunities |
|---|---|---|
| Workflow Automation | AI shifts from being a simple tool to a collaborative partner that understands context & intent | Reduced manual processing time More complex task delegation Better decision support |
| Productivity | Significant efficiency gains across all knowledge work domains | Up to 40–60% time savings Lower cognitive load More time for strategic decision-making |
| Skills Evolution | Professionals must adapt to AI-augmented environments | Learn modern prompt engineering Develop AI collaboration habits Understand where human judgment remains essential |
For Developers & Technical Professionals
Transformations in Coding & Software Development
GPT-5.2 & Gemini 3 Pro push development into a new era:
- More accurate & context-aware code generation
- Advanced debugging with multi-step reasoning
- Better understanding of large, distributed architectures
- Higher accuracy when translating code between languages
- More stable outputs for long, complex workflows
AI Integration Strategy for Modern Developers
To leverage these models effectively, developers should:
- Choose the right model based on latency, reasoning depth & multimodal needs
- Build flexible, modular integration architectures
- Add strong error-handling & fallback mechanisms
- Define ethical guardrails & transparent AI usage policies
Ethical & Practical Considerations
| Dimension | GPT-5.2 Approach | Gemini 3 Pro Approach |
|---|---|---|
| Transparency | Clear reasoning traces, step-based outputs | Explanations enriched with multimodal context |
| Bias Mitigation | Improved contextual reasoning to reduce skewed outputs | Curated & diverse training datasets |
| User Control | Granular, user-selectable modes for creativity, logic & safety | Adaptive privacy settings tuned to user intention |
Conclusion
We’re standing at the threshold of a technological transformation that’s more than just incremental. GPT-5.2 represents a pivotal moment in AI evolution. This isn’t just another technological upgrade it’s a fundamental shift from experimental tools to essential infrastructure. OpenAI is redefining how AI integrates into our work, innovation, and software development.
For users, developers, and enterprises, this new generation of models signals a more capable, intelligent, and collaborative AI future, a transformative approach to how technology understands and supports human potential.
The journey of AI has entered an exciting new chapter.



{kind=link}