
Mistral has been shipping specialized models for a while now. One for coding. One for reasoning. One for chat. Each one doing its thing separately and requiring a different deployment decision.
Medium 3.5 ends that confusion. One 128B dense model, one set of weights, handling instruction following, reasoning, and coding together. Mistral didn’t just release a new model, they retired three existing ones to make room for it. Devstral 2, Magistral and even Medium 3.1 is gone. Medium 3.5 is what replaced all of them.
That’s either a sign of real confidence or a very expensive consolidation bet. Looking at the benchmarks, it’s starting to look like the former.
Table of Contents
What they actually built
128B parameters, dense architecture, no mixture of experts routing. That’s a deliberate choice in an era where everyone is going sparse. Dense means predictable, same compute per token every time, no routing overhead, no expert load balancing headaches in production.
The context window sits at 256K tokens. Vision is built in. Mistral trained the encoder from scratch to handle variable image sizes and aspect ratios rather than bolting on an existing one. Reasoning effort is configurable per request, meaning the same model handles a quick chat reply and a complex multi-step agentic run without switching between deployments.
But before anything else: the license is a modified MIT, not standard MIT. Commercial use is allowed but companies above a certain revenue threshold hit exceptions. Mistral has been loose with the word open source here and that’s worth knowing before you build on it. More on that later.
The three models it replaced and why
Devstral 2 was Mistral’s dedicated coding agent. It lived inside their Vibe CLI and handled agentic coding tasks specifically. Medium 3.5 now powers Vibe instead and according to Mistral’s own benchmarks, it outperforms Devstral 2 across every agentic benchmark they ran.
Magistral was their reasoning model. The one you reached for when you needed the model to think carefully through a problem. Medium 3.5 replaces it in Le Chat with configurable reasoning effort that toggles between fast response mode and deep reasoning mode per request. Same deployment, two behaviors.
Medium 3.1 was the previous generation of this exact tier. The internal comparison tells that cleanly. TAU3 Telecom went from 60.5 on Medium 1.2 to 91.4 on Medium 3.5. TAU3 Airline from 53.5 to 72.0. TAU3 Retail from 70.2 to 76.1. These are the kind of numbers that make you question why you’d keep the old version around at all.
Mistral retire those models because Medium 3.5 made them redundant.
Related: Mistral Small 4: The Open Source Model Replacing Three of Mistral’s Own AI Models
The agentic numbers
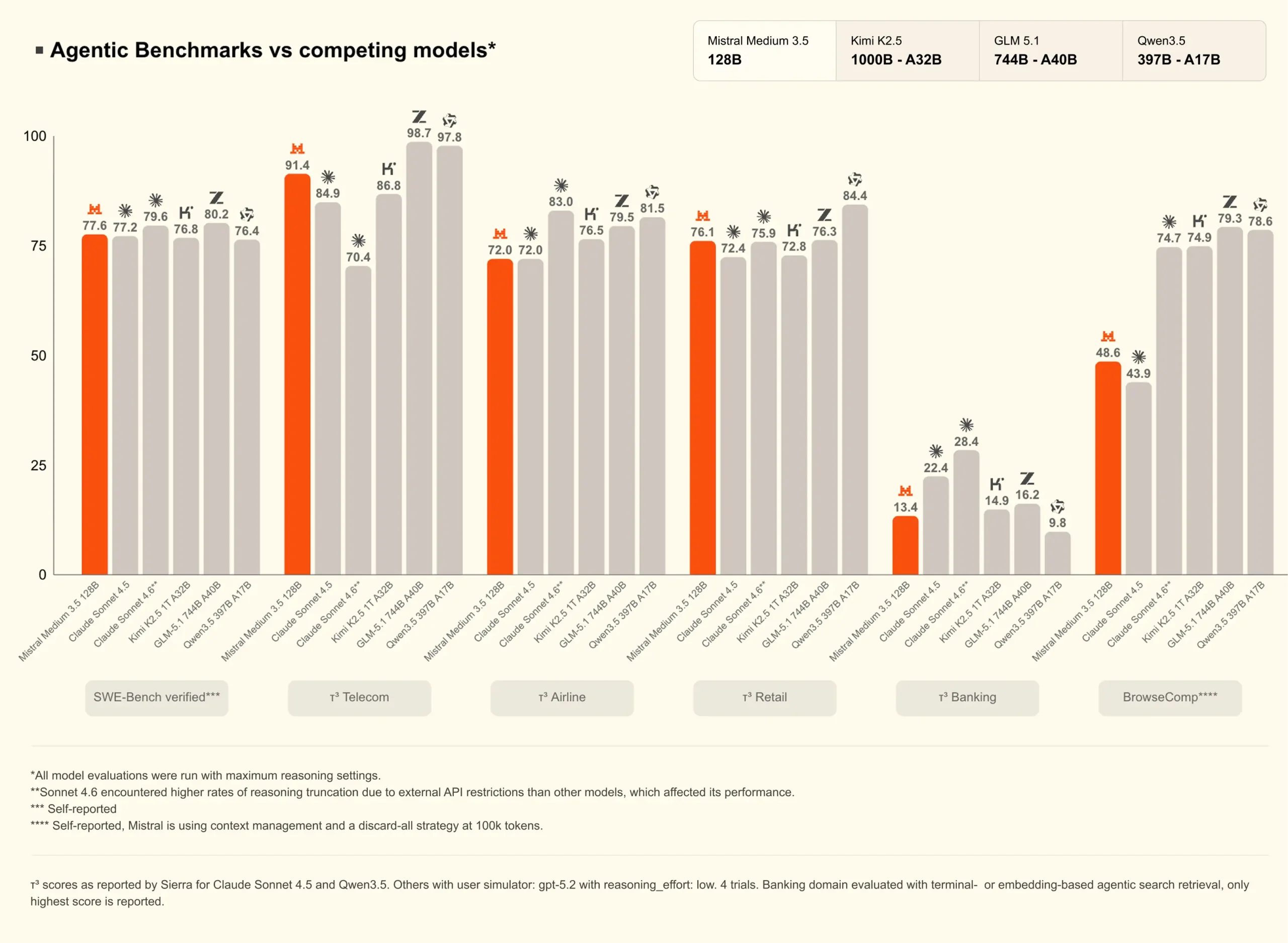
SWE-bench Verified at 77.6 is the headline coding result. For context Claude Sonnet 4.6 sits at 79.6, Claude Sonnet 4.5 at 77.2, and Kimi K2.5 at 76.8. Medium 3.5 is in that conversation, not leading it but genuinely competitive with models that get significantly more attention.
Where it pulls ahead is TAU3 Telecom. 91.4 against GLM-5.1’s 98.7 and Qwen3.5’s 97.8 those two lead, Medium 3.5 is third. On TAU3 Airline it scores 72.0, matching Claude Sonnet 4.5 exactly. TAU3 Retail at 76.1 sits between Sonnet 4.5 at 72.4 and Sonnet 4.6 at 75.9.
BrowseComp is where it gets more honest. 48.6 against Kimi K2.5’s 74.7 and Claude Sonnet 4.5’s 43.9. Ahead of Sonnet 4.5, well behind Kimi. TAU3 Banking at 13.4 is the weakest number. Claude Sonnet 4.5 at 22.4 and Kimi at 14.9 both tell you this category is hard across the board, but 13.4 is still the bottom of that chart.
Medium 3.5 competes in agentic coding and multi-step execution. It doesn’t dominate. It earns its place in the conversation without being the clear winner of it.
Benchmarks
| Benchmark | What it tests | Mistral Medium 3.5 | Claude Sonnet 4.6 | Kimi K2.5 | GLM-5.1 |
|---|---|---|---|---|---|
| SWE-bench Verified | Real GitHub issue resolution | 77.6 | 79.6 | 76.8 | 80.2 |
| TAU3 Telecom | Multi-step agent execution | 91.4 | 70.4 | 86.8 | 98.7 |
| TAU3 Airline | Multi-step agent execution | 72.0 | 83.0 | 76.5 | 79.5 |
| TAU3 Retail | Multi-step agent execution | 76.1 | 75.9 | 72.8 | 76.3 |
| TAU3 Banking | Multi-step agent execution | 13.4 | 28.4 | 14.9 | 16.2 |
| BrowseComp | Web browsing and research | 48.6 | 43.9 | 74.7 | 74.9 |
All comparisons are against Mistral’s own published benchmarks. Self-reported results, standard condition applies.
One thing to note that TAU3 Banking at 13.4 is low across every model on this chart. That’s less a Mistral problem and more a signal that banking domain agent tasks are genuinely hard for current models regardless of who built them.
You May Like: SenseNova-U1: Open Source AI That Understands and Generates Images in One Model
The license question
The actual license is a modified MIT with revenue exceptions for companies above a certain size. That’s not standard MIT and it’s not Apache 2.0.
For individual developers, small teams, and most startups this won’t matter day to day. Commercial use is allowed within the license terms. But if you’re at a company with significant revenue and you’re planning to build production systems on top of this, read the full modified MIT license before committing. The exceptions are real and the definition of what triggers them matters.
Mistral has been consistently loose with the “open source” label across their releases. This one follows that pattern. Open weight with a permissive custom license is the accurate description. Worth knowing before you architect around it.
How to try it
Available on Ollama for the quickest start. GGUFs from Unsloth work through llama.cpp and LM Studio support is listed as work in progress. For production serving vLLM and SGLang both have day-one support. EAGLE speculative decoding is available for both to speed up local inference if latency matters.
For most developers the Mistral API is the practical starting point before committing to local infrastructure. The model powers Le Chat now so you can get a feel for it there without any setup.
One important note if you’re using GGUFs: there was a bug in the original Transformers config that caused long-context performance degradation. Make sure any GGUF you download was generated after the fix was merged. Older files will give you subpar results especially on long sessions.
Who should care
If you were already using Devstral 2 for agentic coding this is your direct upgrade. Same workflow, better numbers, one fewer deployment to maintain.
If you were using Magistral for reasoning tasks, Medium 3.5 covers that with configurable effort. The convenience argument alone is worth evaluating.
If you’re building production agentic systems and need a model that handles coding, reasoning, and instruction following in one deployment without managing multiple specialized models, this is the most direct answer Mistral has given to that problem.
128B dense is not consumer hardware. You’re looking at serious GPU infrastructure or the Mistral API for anything production grade. If that’s not your situation, the model is still accessible via Ollama for evaluation but local inference at full precision needs decent hardware.
Also if revenue thresholds matter to your legal team, get the modified MIT terms reviewed before building on this.



{kind=link}