
Zyphra just dropped a model that’s doing something most people will scroll past without understanding why it’s interesting.
ZAYA1-8B matches DeepSeek-R1 on math benchmarks. Stays competitive with Claude Sonnet 4.5 on reasoning. Closes in on Gemini 2.5 Pro on coding. These are frontier model comparisons, the kind of numbers that usually come with billions of parameters and serious hardware requirements.
This one runs on less than 1 billion active parameters. And it was trained entirely on AMD hardware, which almost no serious model can say.
Built on AMD Instead of NVIDIA.
Every model you’ve heard of was trained on NVIDIA hardware mostly on H100s, A100s, GB200s. The entire open source AI ecosystem has been built on a de facto NVIDIA monopoly and most labs don’t even mention the hardware because there’s nothing to mention, it’s always NVIDIA.
Zyphra trained ZAYA1-8B end to end on AMD Instinct MI300X GPUs. Pretraining, midtraining, supervised fine-tuning, all of it on a 1,024 node AMD cluster built with IBM using AMD Pensando Pollara interconnect.
That detail matters for two reasons. First it proves the AMD stack can produce frontier-competitive results at this scale, which matters for anyone thinking about infrastructure that isn’t locked into NVIDIA pricing.
Second it means Zyphra had to solve real engineering problems that most labs never encounter because they default to CUDA. The fact that the model performs this well coming off that stack says something about both the hardware and the team. It’s a proof of concept for an alternative path that the industry needs.
Less than 1B active parameters.
ZAYA1-8B is a mixture of experts model with 8.4B total parameters and 760M active at inference time.
In a standard dense model every parameter fires for every token. In a MoE model only a subset of experts activates per token, the rest sit idle. ZAYA1-8B takes that further than most. At 760M active parameters it’s running inference at a cost closer to a sub-1B dense model while drawing on the knowledge stored across 8.4B total parameters.
That’s not a new idea, mixture of experts models have been doing this for a while. What Zyphra did differently is push the active parameter count lower than anyone has at this performance level, and back it up with a custom attention mechanism that keeps reasoning quality high even as the active parameter budget shrinks.
AIME 2026 at 89.1 against Mistral Small 4 at 119B total parameters scoring 86.4. HMMT February at 71.6 against the same model’s 70.6. LiveCodeBench at 65.8 against Mistral Small 4’s 57.9. Those aren’t close races for a model running at 760M active parameters against one running at 6B active.
You May Like: Best AI Coding Models for Consumer Hardware
The math and coding numbers
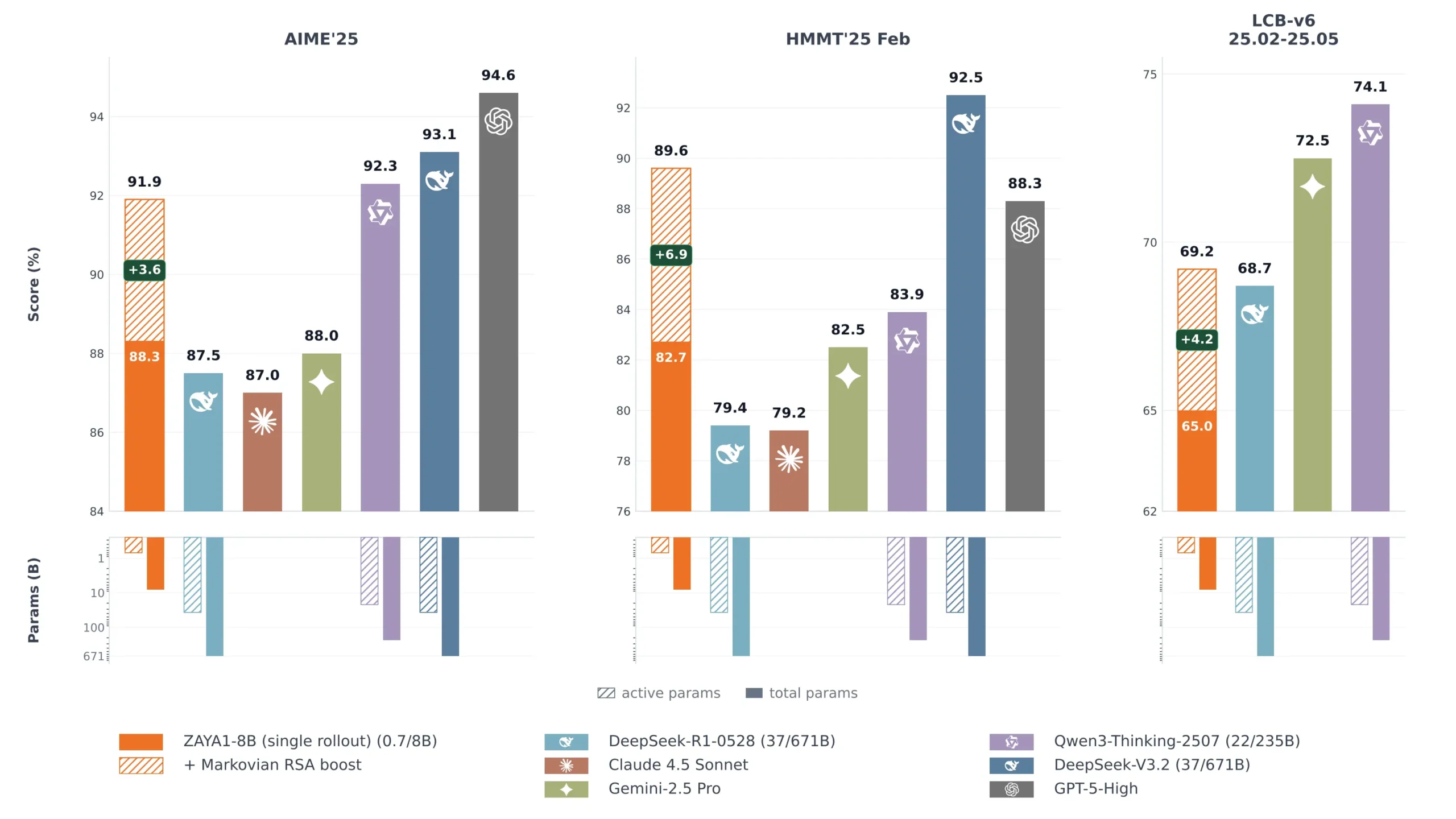
Zyphra reports two sets of scores. base scores and RSA-boosted scores. The base scores are what the model produces without any special test-time compute method. The RSA scores use Zyphra’s novel inference method that generates multiple reasoning traces in parallel and aggregates them. Both are real results but they represent different compute budgets and it’s worth knowing which number you’re looking at.
The base scores alone put ZAYA1-8B ahead of DeepSeek-R1-0528 and Claude Sonnet 4.5 on AIME 2025 and HMMT. With RSA the gap increases further. On LiveCodeBench the base score less than Gemini 2.5 Pro but stays competitive with DeepSeek-R1.
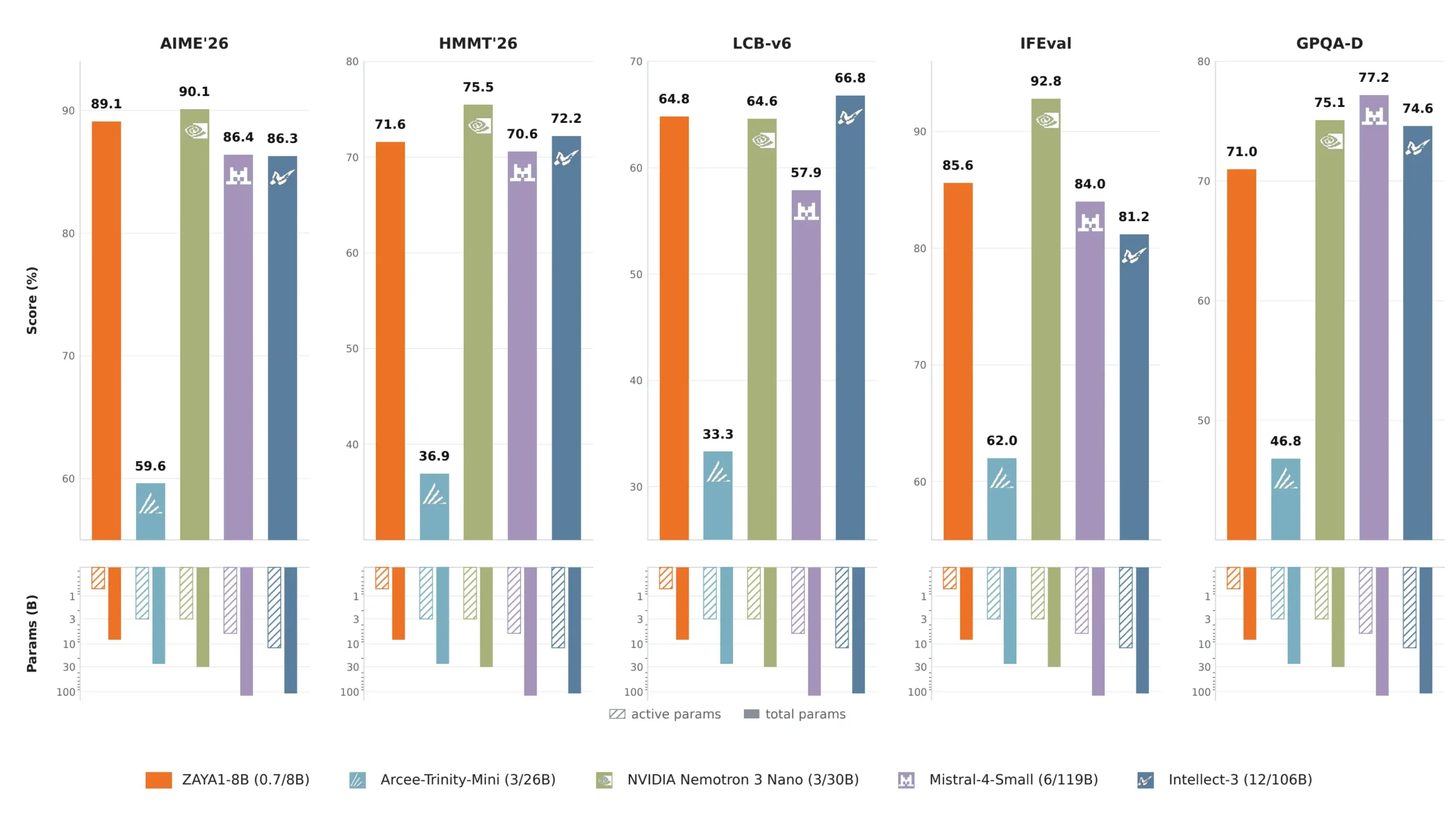
The in-class comparison is even more striking. Against models of similar total parameter count like Qwen3-4B, Gemma 4 E4B. ZAYA1-8B leads across every math benchmark by significant margins. AIME 2026 at 89.1 against Qwen3-4B-Thinking’s 77.5. HMMT at 71.6 against Qwen3-4B’s 60.8.
All numbers are from Zyphra’s own evaluation.
You May Like: DeepSeek-V4 Can Hold Your Entire Codebase in One Context Window and It’s Open Source
Markovian RSA: Why This Model Gets Better the More You Let It Think
Most models give you one shot at the answer. More compute doesn’t help because the reasoning happens once and stops.
Test-time compute methods try to change that. The basic idea is generating multiple answers in parallel and picking the best one. It works but it has a problem, as reasoning chains get longer the context window fills up and the model loses track of where it started.
Markovian RSA is Zyphra’s solution to that specific problem. Instead of one long reasoning chain, the model reasons in chunks. Each chunk generates multiple parallel traces, extracts just the tail end of each trace, the part that actually matters for the next step and uses those as seeds for the next round. The context window stays bounded no matter how long the overall reasoning process runs.
The result is a model that keeps getting better as you give it more compute to think with. On APEX-shortlist with extra-high compute, ZAYA1-8B surpasses DeepSeek-V3.2 and GPT-OSS-High on a challenging mathematics benchmark. That’s a 760M active parameter model outperforming models with tens of billions of active parameters given enough thinking budget.
One important detail Zyphra flags themselves: this works because they trained the model specifically to understand and respond to the Markovian RSA process. When they applied the same method to Qwen3-4B without that co-training, the performance uplift was significantly smaller. The method and the model were designed together.
Limitations of this Model
The math and coding part is impressive but the agentic one is not.
BFCL-V4, which tests reliable function calling, scores 39.22. Qwen3-4B-Thinking hits 49.7 on the same benchmark. TAU2 scores 43.12 against Qwen3-4B-Thinking’s 52.9. These are meaningful gaps and Zyphra doesn’t hide from them, the model was built and optimized for mathematical reasoning and coding, not for multi-step tool use and agent execution.
Instruction following is also mixed. IFEval at 85.58 is solid but IFBench at 52.56 trails Qwen3.5-4B’s 59.2. For tasks that require strict adherence to complex instructions across many steps, there are better options at this size.
Style and chat quality tells the same thing. EQBench at 72.95 and Creative Writing at 62.97 both less than comparable models. This is a reasoning and math specialist, not a well-rounded assistant.
If your use case is math, science, or complex coding problems, ZAYA1-8B is genuinely one of the most interesting small models available right now. If you need reliable tool calling, complex instruction following, or strong general chat quality, the benchmarks are honest about where it falls short.
How to try it
The quickest path is Zyphra Cloud where it runs as a serverless endpoint. For local use the weights are on Hugging Face under Apache 2.0 which is about as clean a license as you get.
One honest heads up for local deployment. ZAYA1-8B requires Zyphra’s own fork of vLLM to run properly. The standard vLLM install won’t work. It’s a one-line install but worth knowing before you assume it drops straight into your existing stack.
Small Model For Science, Maths & Coding
If you work with math, science problems, or complex coding tasks and you’re looking for something small enough to run locally or cheaply via API, this is worth serious evaluation. The benchmark numbers at 760M active parameters are not normal and the Markovian RSA boost means performance scales with compute budget.
If you’re building agent workflows that need reliable tool calling or multi-step instruction following, then there are many great solutions available, you can check these open source agentic models. The agentic numbers are honest about that gap.
Researchers working on test-time compute methods will find the Markovian RSA implementation worth studying regardless of whether they deploy the model itself. The co-design approach, training the model specifically to work with the inference method is an interesting direction that most labs haven’t published on at this level of detail.
The AMD training part is also worth paying attention to if you care about where the hardware ecosystem goes next.



{kind=link}