
Anthropic did not mean to show anyone how Claude Code works. A routine update, a misplaced debug file, and suddenly nearly 500,000 lines of internal source code were sitting on a public npm registry for anyone to download.
The company moved quickly. The version was pulled. A spokesperson confirmed no customer data was exposed. Standard damage control.
But by then it was too late. The code had been mirrored across GitHub, starred 84,000 times and picked apart by developers who had been curious about what was actually running under the hood of one of the most talked about AI coding tools of the past year.
What they found was not just how Claude Code works today. It was a window into what Anthropic is building next. And that is the part worth talking about.
Table of contents
What actually happened
On March 31 2026, Anthropic pushed version 2.1.88 of the Claude Code npm package. Bundled inside was a source map file, a tool normally used for internal debugging that is never meant to ship publicly. That file pointed to a zip archive on Anthropic’s own cloud storage containing the full Claude Code source code.
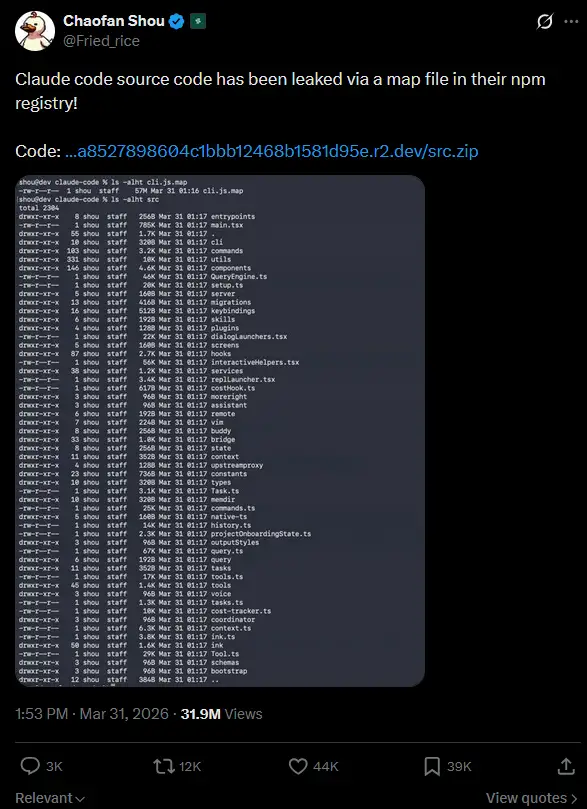
Security researcher Chaofan Shou spotted it first and flagged it publicly on X. The post crossed 28 million views. Within hours developers had downloaded, mirrored and published the code to GitHub where it quickly accumulated over 84,000 stars.
Anthropic pulled the version from npm and confirmed the incident. “This was a release packaging issue caused by human error, not a security breach,” a spokesperson said. No customer data or credentials were involved.
The code is still accessible via mirrors. Anthropic has issued at least one takedown notice but the contents are effectively public at this point.
The features nobody knew about
This is where it gets interesting. Developers who dug into the leaked code found more than just the current Claude Code architecture. They found fully built features that have not shipped yet, complete with internal names and system prompts.
The one getting the most attention is KAIROS. It appears to be a persistent background agent mode that lets Claude Code keep working even when you are idle. Not a session that waits for your next prompt. An agent that runs on its own, fixes errors, executes tasks and sends you push notifications when something needs your attention.
Then there is something called dream mode. Based on what developers found in the code, it appears designed to let Claude think continuously in the background, developing ideas and iterating on existing work between active sessions. The self healing memory architecture complements this, allowing Claude to review what it did in a previous session and carry learnings forward into the next one.
The multi agent orchestration system is also in there. Claude Code can apparently spawn sub agents, smaller instances that handle specific parts of a complex task in parallel, then feed results back to the main agent.
None of this is officially confirmed as shipping features. These are findings from the leaked source. Anthropic has acknowledged the code is real but has not commented on specific unreleased capabilities beyond confirming they exist as feature flags that are fully built but not yet released.
The Undercover Mode situation
This is the one that generated the most dramatic headlines. And it is worth reading carefully before making conclusions. The leaked code contains a system prompt for something called Undercover Mode. The exact wording found in the source: “You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository. Your commit messages, PR titles, and PR bodies MUST NOT contain ANY Anthropic-internal information. Do not blow your cover.”
Reading that cold, it sounds alarming. But the instruction is specifically about not leaking Anthropic internal information into public commits. Not about hiding that AI was involved. Not about deceiving contributors. About keeping internal Anthropic context out of public facing repository activity.
Anthropic has not officially explained the feature or its intended use. So we are working from the code itself and what developers have reported finding. Draw your own conclusions.
What is worth noting independently is the broader question this raises. If AI tools are making commits to public open source repositories, should those contributions be identifiable? That conversation is happening in the developer community right now and this leak accelerated it.
You may Like: Small But Powerful AI Models You Can Run Locally on Your System
What this means for competitors
Anthropic did not just accidentally publish a debug file. It accidentally published a detailed engineering blueprint for building a production grade AI coding agent. The multi agent orchestration system, the context management pipeline, the memory architecture, the tool definitions, the query engine handling LLM API calls. All of it is now public. Any team building a competing coding agent just received a free education on how one of the most used tools in the space actually works under the hood.
AI security company Straiker put it plainly. Instead of guessing how Claude Code handles context, attackers and competitors alike can now study exactly how data flows through its four stage context management pipeline.
That cuts both ways. Bad actors now have a clearer picture of where to look for vulnerabilities. But open source developers also have a clearer picture of how to build something comparable.
The irony is not lost on the open source community. A tool that has benefited enormously from open source foundations just had its own internals made public involuntarily. Some developers are already treating the leaked codebase as a reference implementation.
Anthropic has issued takedown notices. The code remains widely accessible.
Also Read: Open Source AI agentic models built for real autonomous work
The most valuable open source contribution Anthropic never meant to make
Anthropic will patch the process, tighten the packaging pipeline and move on. The leaked version is already pulled from npm. Life continues.
But the codebase is out there. Mirrored, starred, forked and studied by thousands of developers who now have a clearer picture of what a production grade AI coding agent actually looks like inside.
The unreleased features are the real story. KAIROS, dream mode, persistent memory, multi agent orchestration. These are not research concepts. They are fully built and waiting to ship. That tells you more about where AI coding agents are heading in the next six months than any product announcement would have.
For the open source community specifically, the irony cuts deep. A tool built on top of open source foundations, used by developers who live and breathe open code, accidentally became the most detailed public reference implementation for building an AI coding agent that exists right now. Anthropic did not mean to contribute this. But here we are.



{kind=link}