
On Sunday, Shopify CEO Tobi Lütke did something most machine learning engineers spend months trying to achieve. He improved a core model’s performance by 19% while he was asleep & didn’t use a massive compute cluster or a team of researchers. He used a 630-line weekend project released by Andrej Karpathy (former co-founder of OpenAI), called autoresearch.
By the time he woke up, the agent had run 37 experiments, tested dozens of hyperparameter combinations, and handed him a 0.8B model that outperformed the 1.6B model it was meant to replace.
Karpathy’s response when he heard? “Who knew early singularity could be this fun.”
That’s the story everyone is sharing. But the more interesting story is what autoresearch actually is, how it works, and what it quietly says about where AI research is heading.
Table of contents
So What Actually Is Autoresearch?
Think of it as a self-running research lab that fits on a single GPU.
Karpathy built it on top of his own nanochat training core, stripped down to just 630 lines of code. The whole thing revolves around three files. A data prep file that never gets touched. A training script that the AI agent edits freely. And a Markdown file called program.md that you write yourself.
That last one is the key. You don’t touch Python. You write plain English instructions telling the agent what to try and what to optimize for. The agent takes it from there.
Every experiment runs for exactly five minutes. If the model improves, the change gets committed. If it doesn’t, it gets rolled back automatically. Then it runs another experiment. And another. All night if you want.
At roughly 12 experiments per hour you can wake up to over 100 completed experiments and a model that’s genuinely better than the one you went to sleep with.
That’s it. No complex setup required.
The Overnight Experiment That Changed How I Think About AI Research
Lütke wasn’t doing anything exotic. Before going to bed he pointed the agent at an internal query expansion model, wrote instructions telling it to optimize for quality and speed, and let it run. Eight hours later he had a log of 37 completed experiments, each one tested, evaluated, and either kept or discarded automatically.
He described watching the agent reason through experiments as mesmerizing and said he learned more from that single overnight run than from months of following ML researchers.
That’s not a small claim. Lütke runs one of the largest e-commerce platforms in the world and has been building software for decades. When someone like that says an overnight agent run taught him more than months of conventional research, it’s worth paying attention to.
The result was a 0.8B model that outperformed the 1.6B model it was meant to replace. A smaller, faster, cheaper model — discovered automatically overnight.
Karpathy’s response when he heard: “Who knew early singularity could be this fun.”
The Ratchet: Why It Only Gets Better and Never Worse
The cleverness of autoresearch isn’t the AI part. It’s the ratchet mechanism underneath it.
Every experiment is measured using validation bits-per-byte, a metric that works regardless of model size or architecture changes. If an experiment improves that number, the change gets committed to a git branch and becomes the new baseline. If it doesn’t improve, git resets it like it never happened.
The agent never goes backwards. Every kept change builds on the last one. Over time the model only moves in one direction.
The fixed five minute training window is what makes this work cleanly. Every experiment runs for exactly the same amount of time regardless of what the agent changed — model size, batch size, architecture, optimizer settings. That makes every experiment directly comparable. No experiment gets an unfair advantage just because it ran longer.
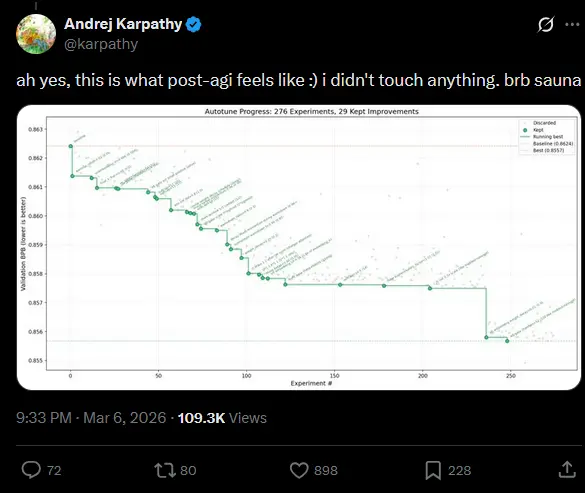
In Karpathy’s own runs on 8x H100 GPUs, the agent completed 276 experiments over multiple days and kept 29 improvements. More importantly, the improvements discovered on a smaller depth 12 model transferred cleanly to a depth 24 model. The agent wasn’t just finding lucky shortcuts. It was finding genuinely meaningful insights.
The Real Division of Labor
This is the part many are missing about AutoResearch
The headline is “AI runs experiments automatically.” But what that actually means for the person using it is more interesting. You are no longer the one editing Python files, tweaking hyperparameters, and waiting for training runs to finish. That entire cycle gets handed off.
What you’re left with is program.md.
A Markdown file. Plain English. You write what you want the agent to try, what you want it to optimize for, what constraints matter. The cleaner and more precise your instructions, the better the agent navigates the search space. The quality of your research org is now determined by how well you can write a strategy document, not how well you can write a training loop.
Karpathy has talked about this shift before. The primary user of many systems is increasingly an LLM, not a human. Autoresearch makes that concrete. The human becomes the strategist. The agent becomes the executor.
Also Read: Just After Launching Qwen3.5, Qwen’s Core Team Walked Out. Is This the Last Great Qwen Model?
Does It Actually Work?
The Shopify result is compelling but it’s one overnight run by a non-ML engineer. Fair to ask if it holds up beyond that.
Karpathy’s own runs answer that. On the bigger nanochat system using 8x H100 GPUs, the agent ran 276 experiments across multiple days. 29 improvements were kept. Validation loss moved steadily downward across the entire run.
The more interesting result is what happened when those improvements were tested on a larger model. The insights discovered at depth 12 transferred cleanly to a depth 24 model. That matters because it means the agent wasn’t just finding lucky tricks that work at one specific scale. It was finding something more fundamental about the architecture and training setup.
Karpathy notes in the README that the codebase is allegedly in its 10,205th generation. He admits nobody could verify that at this point. The self-modifying nature of the system makes it genuinely hard to trace every change back to its origin.
That’s either exciting or unsettling depending on how you look at it. Probably both.
What You Actually Need to Run This
The honest answer is that the base project was tested on H100 GPUs. That’s enterprise hardware, not something sitting on most desks.
But the community moved fast. Within days of the release forks appeared for MacOS, Windows with consumer RTX cards, and Apple Silicon. Karpathy himself acknowledged the interest and left guidance in the README for tuning the defaults down to smaller hardware, lower model depth, smaller sequence length, reduced vocabulary size.
If you want to run the base project as Karpathy intended, you need a single NVIDIA GPU with enough VRAM to handle the training loop. For the community forks targeting consumer hardware the bar is lower but results will vary depending on your setup.
The project uses the uv package manager which keeps the setup clean. Three commands and you’re running your first experiment. The complexity is in the program.md you write, not in getting the thing installed.
If you want to try it on smaller hardware the MacOS fork by miolini and the Windows RTX fork by jsegov are the most active starting points right now.
So Is Autoresearch a Singularity?
Autoresearch isn’t the singularity. Karpathy himself would be the first to tell you that. It’s a weekend project, deliberately minimal, scoped to one GPU, one file & one metric.
But it does close a loop that researchers have been thinking about for a long time. AI being used to improve the very training code that produces better AI. That’s not theoretical anymore. It’s a GitHub repo with an MIT license and 12.8K+ stars.
The shift it points toward is worth sitting with. The researcher’s job used to be writing training code and running experiments manually. Now it’s writing program.md and letting the agent handle the cycle. The best research orgs of the next few years probably won’t be the ones with the most compute. They’ll be the ones who write the best program.md.
We aren’t at the Singularity yet. But we are officially at the point where your GPU works harder while you’re asleep than most of us do while we’re awake.



{kind=link}