
Alibaba gave Qwen3.7-Max a kernel optimization task on a hardware platform the model had never encountered before. No documentation or profiling data. No example kernels for the architecture. Just a task description, an existing implementation, and an evaluation script.
The model ran for 35 hours. It made 1,158 tool calls. It wrote, compiled, profiled, and rewrote the kernel repeatedly, diagnosing failures, fixing bugs, identifying blocks, and redesigning the architecture multiple times without anyone watching. After 30 hours it was still finding meaningful improvements.
The final result was a 10x speedup over the reference implementation.
For context: GLM 5.1 ran the same task and reached 7.3x. Kimi K2.6 reached 5x. DeepSeek V4 Pro reached 3.3x. The models that stopped early did so because they issued no tool calls for five consecutive rounds, they concluded they couldn’t make further progress and stopped. Qwen3.7-Max didn’t stop.
Table of Contents
What the task actually was
The kernel in question is Extend Attention, a production component in SGLang, a widely used inference framework. Specifically it handles attention between newly generated tokens and a prefix KV-cache of up to 32K entries, a memory-bound, latency-critical operation that directly affects how fast LLMs serve responses.
The hardware was T-Head ZW-M890 PPUs, a processor architecture that wasn’t in any training data. The model had no prior knowledge of how it behaved. It started cold.
Over 35 hours it performed 432 kernel evaluations. Each cycle meant writing code, compiling it, running it, reading the profiling output, deciding what to change, and trying again. The model diagnosed compilation failures it hadn’t seen before, identified performance bottlenecks through runtime feedback rather than prior knowledge, and redesigned the kernel architecture multiple times when incremental improvements stopped working.
This matters because it tests something different from standard benchmarks. Most evaluations measure whether a model can produce a correct answer given a well-defined problem. This one measured whether a model could sustain coherent strategy across more than a thousand tool calls on an open-ended optimization problem with no human guidance. Those are different skills and most models don’t have it.
What Benchmarks Shows
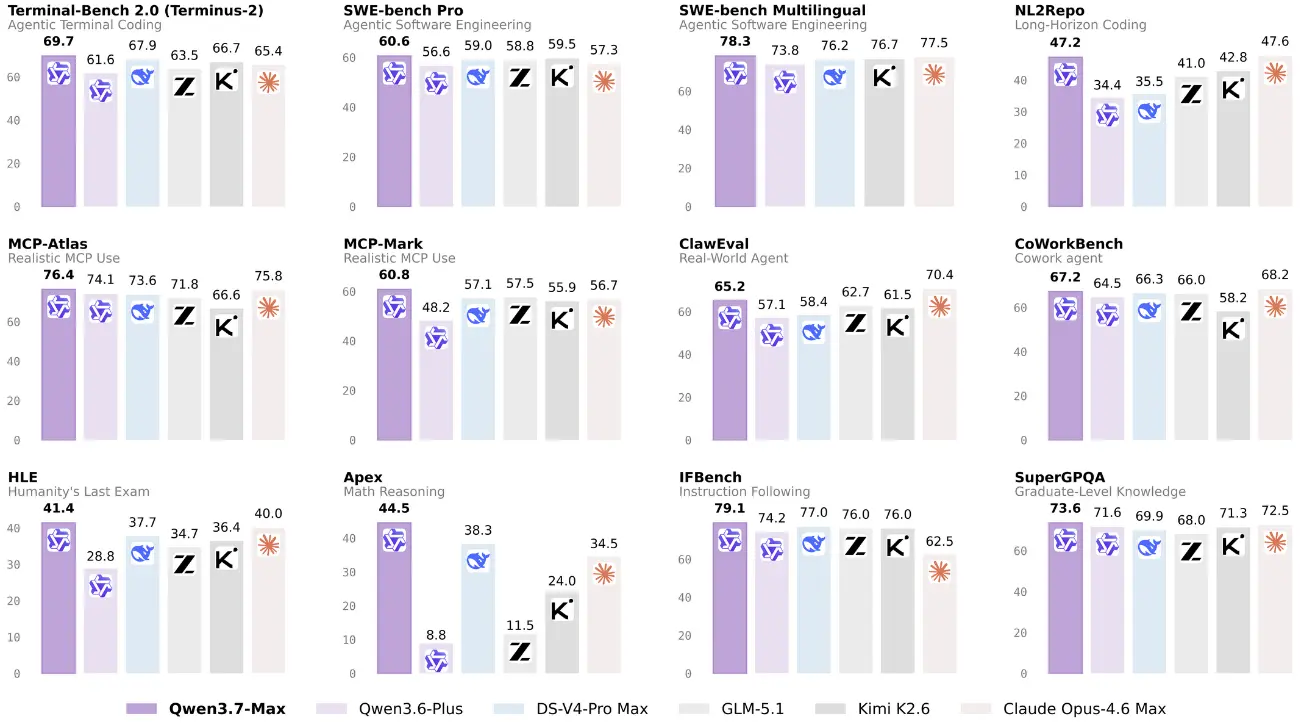
The numbers below are from Alibaba’s own evaluation.
| Benchmark | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro |
|---|---|---|---|
| SWE-Verified | 80.4 | 80.8 | 80.6 |
| Terminal Bench 2.0 | 69.7 | 65.4 | 67.9 |
| GPQA Diamond | 92.4 | 91.3 | 90.1 |
| HLE | 41.4 | 40.0 | 37.7 |
| HMMT 2026 Feb | 97.1 | 96.2 | 95.2 |
| BFCL-V4 | 75.0 | 76.7 | 70.6 |
On coding agents it trades blows with Opus 4.6 and DeepSeek rather than clearly beating either. Terminal Bench is the exception where it leads. The reasoning numbers are where the gap opens up more consistently, GPQA Diamond, HLE, and HMMT all show Qwen3.7-Max at or above the strongest available comparison points.
The remaining benchmarks gives you clear idea , if its a right model for your use case.
You May Like: ByteDance Open-Sourced a 3B Model for Images, Video, Editing, and Reasoning
Why this model trains differently
Most models get better by seeing more text. Qwen3.7-Max got better by seeing more situations.
Alibaba calls it environment scaling. Instead of optimizing for specific benchmarks, they built a large and diverse set of agentic training environments, different tasks, different tools, different harnesses, and trained the model across all of them. The idea is the same as why a model trained on diverse text generalizes better than one trained on narrow text. Diversity of experience produces capability that transfers.
The practical result is cross-harness generalization. Qwen3.7-Max performs consistently whether it’s running through Claude Code, Qwen Code, or a custom tool-use framework. It learned to solve problems rather than learn the patterns of a specific scaffold. That’s rarer than it sounds, most agentic models quietly overfit to the evaluation setup they were trained on.
Limitations
It’s a proprietary API model. No open weights, no local deployment or self-hosting. For teams with data privacy requirements or anyone who wants to run models on their own infrastructure, that’s a hard stop regardless of the benchmark numbers.
The instruction following gap is also real. IFBench at 79.1 is strong but lower than some competitors on complex multi-step instruction adherence. For workflows that require strict formatting or on-point output structure across long sessions, that’s worth testing before committing.
And the benchmark table is entirely self-reported. Alibaba ran these evaluations. Independent reproduction will clear the complete picture.
You May Like: Open source AI agentic models built for real autonomous work
Who is this for?
A model that ran autonomously for 35 hours on hardware it had never seen, kept improving past the 30-hour mark, and finished 10x faster than the reference implementation is not a normal result. The benchmark numbers are competitive with the best available models. The kernel run is in a different category of evidence entirely.
If you’re building agentic workflows and can work within a proprietary API, this is worth serious evaluation. If open weights are a requirement, it isn’t an option yet. That’s the whole story honestly told.



{kind=link}